
Articles and Blog
On
Looting: To Address It or Not
A Fifth of Bootheaven - Dual Boot is for Tourists!
Attribution Dice (The
Mobile Twist)
Masque
of the Green Death, or, Those Old Coronavirus Blues
HOWTO:
LUKS Encryption in Ubuntu 18.04
A Brief Exemplar of Social Engineering
Memo
to Google (an Ongoing Series)
Big
Data Forecast for the Week
Marshmallow's Terrible, Horrible, No Good, Very Bad MP3 Player
HOWTO:
S/MIME Setup in Thunderbird
CompTIA Security+ Certification Study Notes
Where
ideas come from (and where they go)
Diet
BOINC: A Screen Saver Module
Bitcoin:
Observations and Thoughts
Fun in
the Sun: A Solar Powered Laptop
LAMP, the Linux and Everything
Tweons:
Horribly Helpless Twitter Peons
WordPress
Conversion - Episode III: A New Nope
WordPress Conversion - Continued
WordPress
Conversion - Prologue
The Sony Hack, Strategic Questions and Options
The
Human Factor in Tech Models
HOWTO: Linux, Chromium and Flash Player
To
Kill a Mockingbird, Once and Only Once
Kill Switches and Other Mobile Realities
HOWTO: Automate temperature monitoring in CentOS Linux (a/k/a Build your own Stuxnet Day)
Wallpaper,
Screensavers and Webcams, oh my!
HOWTO: Run BOINC / SETI@Home over a Samba Server
Proper
Thinking about Computer Privacy Models
Philosophy of Technology (Kickstarter project)
Repetitive
Motion Injuries and the Computer Mouse
HOWTO: Set up a Static IP on Multiple Platforms
HOWTO:
Check if your Windows XP computer can be upgraded to
Windows 7 or Windows 8
Tweeting This Text and That Link (tweet2html.py)
Deputy
Level Heads Will Roll - The Obama IRS Scandal
Kids and Personal Responsi-woo-hoo (on Reverse Social Darwinism)
Learning New Subjects on the Cheap
The
End of Life (of Windows XP)
Women's Magazines: In a Checkout Line Near You (for International Women's Day)
HOWTO: Blackberry as Bluetooth Modem in Linux
Mandiant
on Advanced Persistent Threats
Examining Technological Vulnerability
HOWTO: Install WinFF with full features in CentOS Linux
The Age
of the Technology License?
Information
Systems: Where We are Today
Big
Business Really Is Watching You
Where are the UFOs?
With the upcoming US government report on UFO sightings over the years and what they mean or not, it is perhaps time to review that wonderful gem: Drake's Equation.
Drake's Equation is stated thus:
N=R*fpneflfifcL
N = The number of civilizations in the Milky Way galaxy whose electromagnetic emissions are detectable.
R* = The rate of formation of stars suitable for the development of intelligent life.
fp = The fraction of those stars with planetary systems.
ne = The number of planets, per solar system, with an environment suitable for life.
fl = The fraction of suitable planets on which life actually appears.
fi = The fraction of life bearing planets on which intelligent life emerges.
fc = The fraction of civilizations that develop a technology that releases detectable signs of their existence into space.
L = The length of time such civilizations release detectable signals into space.
(source: Space.com, https://www.space.com/25219-drake-equation.html)
I've always especially liked Drake's Equation because it looks scientific (and it is), yet at the same time, the point of the equation not to predict whether there is life out there, but rather to demonstrate that we cannot know based on the information that we have now.
Consider:
R* = The rate of formation of stars suitable for the development of intelligent life.
UNKNOWN. Stars form differently, we believe that much. Some stars have too much gravity to support a planetary system, some have too much radiation. Nor are we remotely near surveying all stars.
fp = The fraction of those stars with planetary systems.
UNKNOWN. At this point we can only make a best guess based on telescopic observation of change in light around stars to guess whether there is anything revolving around those stars. Also, as above we are not remotely near to having surveyed all stars we can see, let alone planets.
ne = The number of planets, per solar system, with an environment suitable for life.
UNKNOWN. If there are billions of stars, and we cannot survey all of them, that number increases exponentially when we consider all of the planets to be surveyed, even assuming that we have the technology to make meaningful observations.
fl = The fraction of suitable planets on which life actually appears.
UNKNOWN. There is another principle called the Goldilocks Principle which says that not only must a planet be at a distance from its star that life can form, but in fact it must remain at such a distance (not too hot, not too cold, but just right) for the unknown but bogglingly long time (allowing for asteroids and other life killing disasters) necessary for life to evolve.
fi = The fraction of life bearing planets on which intelligent life emerges.
UNKNOWN. We have one example to draw on: Earth. Not only is one example a ridiculous metric for extrapolation, but in our case, intelligent life is only believed to have developed after the fortuitous extinction of the dinosaurs.
fc = The fraction of civilizations that develop a technology that releases detectable signs of their existence into space.
UNKOWN. Since we only have one example to draw on for extrapolation, Earth, and our own history includes an extinction of life before intelligent life evolved, and because the prior extinction was based on a random element (an asteroid), even if intelligent life has evolved elsewhere and will be inclined to communicate, it may currently be in the equivalent of ancient Rome or the Middle Ages, or even millions of years behind us.
L = The length of time such civilizations release detectable signals into space.
UNKNOWN. Since we can know that we cannot know the place in the timeline of evolution a theoretical civilization is at, we cannot know whether they have already sent signals, or whether they are dozens or hundreds or thousands or millions of years from developing to that point. Also, again based on the one example that we do have with regard to sending detectable signals, we can assume that these signals may take centuries to be detectable once they are sent, and may in fact be in a format we are unable to detect when they do arrive.
In short, shy of a “Klaatu Barada Nicto” moment, there is no proof either way that aliens exist. Whatever you want to believe, fill in the probabilities above as you are inclined, and believe what you will.
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
First Amendment and News
June 6, 2021
I could spend the rest of my life writing on the subject. With degrees in liberal arts and computer science and a penchant for political science, I see more and ask the questions, that, if I had 30 less IQ points, would never occur to me. All of this to say that in the end, like it or not, technology is affected by politics. So, how to address this reality? One can mourn over the connection or face it head on. In the end, the correct approach is somewhere in the middle.
Back in the day, I would leave work and often go to a local restaurant which had several factors in its favor. It served a slightly above average bowl of chili, it offered unlimited and very good black coffee, and it had a newspaper machine outside. I would take at least an hour (and tip for the privilege) sucking down coffee and chili, and reading the paper.
Having read my share of Supreme Court decisions in college, it would never have occurred to me that the concepts of being able to read the news and to do so without unnecessary government interference was NOT a First Amendment issue. Of course it would be! There is no point to having the right to report the news if there is not a corresponding right to consume the news.
Recently the FBI applied for a subpoena (quashed) to obtain the IP addresses of all people who read a certain USA Today news article. To a tech educated thinker this was evoked several responses.
- It was not surprising. The information exists, and someone (or more than one someone) will eventually seek to abuse it.
- This concept has existed for years, and has always been problematic. Imagine the person who went from paper newspapers to a first smartphone, and was required to sign in to read the news. 'Wait! You are now going to track, like track-track, what I read?' The younger generation has no basis for comparison unless they are very well read, and being well read these days is both an unpopular and politically questionable position with implications of racism thrown in for good measure.
- The government already tracks what you read in any case. This is not a tinfoil hat conspiracy theory, this is verifiable by anyone who cares to take the time to do so. I cleared all cookies, passwords and other PII from a browser and loaded a mainstream media site. I glanced over the front page and clicked on a tech article about tracking and privacy for added irony, and read that as well. Then I took the browser offline and examined the cookies the site set. Two of the cookies the site set in that short session were for non-US servers, which means that NSA already sucked up the information about who read what.
Given that this information is already recorded, and has been for some time, what is the point of the FBI subpoena? Perhaps not so much to acquire information that they already have or could have, as much as a warning to the public about what not to read. It's a far cry from being able to freely and anonymously consume news. As always, the resolution will finally be political, not technical.
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
On Looting: To Address It or Not
June 4, 2021
The state of technology as it exists today suggests that this is wholly preventable with proper inventory control, and if this is so, would greatly reduce the value of looted items as personal use or resale items, which in turn would reduce the incentive to loot in the first place. A good example of this technology in action is Apple products. In the wake of a New York City looting episode, Apple announced that stolen phones could not be activated, and the question a serious technophile might ask is how Apple could make good on this advisory.
The answer is both technology and business control related, simple enough to implement, and properly applied, need not violate any (rightly) cherished American concept of privacy.
Let's consider two big ticket items of varying functions: a mobile and a smart television (this could apply also to personal computers, tablets or Bluetooth devices just as easily). These items (AS THEY ARE SOLD TODAY) have something in common, that is, they have a serial number programmed into them, and the serial number appears (or could) both in the internal programming of the device itself, and on the packaging of the unit.
This last is important: it suggests that the device serial number is readily available without breaching the consumer packaging. Think about the last high ticket item you purchased (or look at the packaging if you retained it). There will be a coded label which contains the model number, but also a unique serial number for that device. On the packaging. Outside of the box containing the actual product.
Any business which bothers to take the time and effort to do so can scan the bar- or QR- code of all devices which it takes into inventory and create a database containing the serial numbers of every device it currently holds. Upon sale of a given item, the serial number of that item can be removed from inventory. Not only is this not even remotely difficult, inventory control is the very reason that the outside of the box has a model/serial number label in the first place.
So, assuming a company takes 10 items into inventory, serial numbers 1 through 10, simply scanning each item for serial number should update the database with serial numbers accordingly. Companies already do this to record and track model inventory. Let's say that a business buys 25 model AT250 computers. The business needs to be able to track the inventory of model AT250 for its own business model purposes: that is, how well is AT250 selling and when or should we bring in more? Recording the serial number as the item is checked in to inventory, and, as importantly, removing that item and its serial number from inventory as it is sold is, or could be, a basic business model function.
So let's consider the implications as regards looting. In our connected society, the serial number of a device can be checked any number of times. A serial number can be checked
- in inventory control, that is, when the device is received as part of a merchant's inventory
- at checkout, that is, when a device is sold and ceases to be part of inventory
- at use, that is, when the device is registered on the internet or other networks
This last has many implications. Many people do not know this but every call on a mobile device, every ringtone, every app download can and usually does record the unique device identifier (that is, serial number) of the connected device. The same is already or can be true of every computer or smart television. Simply put, for the device to be fully functional, it must at some point, connect to a larger network.
Now suppose that company A has ten computers in inventory. It sells three, removing those devices from inventory every time a sale is made. That leaves seven highly and uniquely identifiable devices in inventory. Now assume a riot and attendant looting causes those remaining seven devices to be stolen. Company A has lost seven highly identifiable and unique devices from inventory. These devices are identifiable by model (since our Company A files an insurance claim based on known lost inventory, this is a given). Stolen items can just as easily be identified by serial number.
Neither Company A nor the police, nor the insurance can say where a looted device is in time and space, but they can know that, to be fully functional, the device must, at some point, register with some online system somewhere. A cable provider, an ISP, a mobile network, an app store. At SOME POINT, to be fully usable, a device must register with some network somewhere.
If a device must register somewhere, it can be prevented from doing so. If a company has the serial number of looted devices, it is a relatively minor technical exercise to prevent this registration. Perhaps the device can be made to verify itself with the manufacturer itself, perhaps the merchant or app market can perform the verification. Perhaps our Company A's insurance carrier insists on it or does it itself. Either way it's a minor technical exercise if the will to do it exists.
Now consider the implications if such a device is looted. Where can it be sold? Where can it be used? If the practical answer is 'nowhere' then the looted device is useless. It cannot be sold in the streets, it cannot be sold online. An individual user will not buy if the device is, or probably is, disabled, an online facilitating merchant like eBay or Amazon will not permit it to be sold if they have to get involved with satisfying a deceived customer. Social justice has its points, but in the end, to invoke Don Corleone, business is business.
There is the naivete question to consider. I am both American and technologically and politically educated. I appreciate the potential for abuse of such a far reaching system. I get it, perhaps more than most people. But, as Tik-Tok and Huawei can be prevailed upon to behave themselves despite their default tendency not to do so, so can any vendor or merchant. The solution is a political, not a technological one.
In the end, this is a question of will more than skill. The technology exists, and merchants (such as Apple, as we have seen) can implement it. It only remains for merchants (or their insurance carriers) to require it to be used properly and on a vendor and product neutral scale.
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
Everybody Plays the Fool - Election 2020
August 28, 2020
I’m from Chicago. Political shenanigans and outright fraud does not surprise me, in fact it amuses me in a been-there-seen-that sense. Seeing Chicago style politics come into its own on the federal level doesn’t so much inspire outrage (although I’ll admit that it should). Rather, it inspires an amused chuckle and analysis for the next step resulting from the first, etc. On that basis, here’s my analysis which concludes with a Biden victory.
This election will be too close for a landslide victory on either side. The opposing philosophies are too drastically in opposition for there to be much crossover. This election as in all presidential elections, but perhaps more so in this case than in the past, will be decided by the swing voters. This is at the balloting level. Enter Chicago style politics.
In addition to an already close election, coronavirus will either cause people not to vote or to vote by mail. Voting by mail is rife with opportunities to cry foul. Absentee ballots by registered voters are considered valid, legal and trustworthy, but in this election absentee ballots are augmented in some states by generic mail in ballots which is not the same thing. And it’s a reason for either party to challenge election results in the courts.
It can be argued that the United States Postal Service practices may impact balloting results. This is neither here nor there, there are valid reasons why the postal service has reduced capacity. This includes adoption of online communications and commerce by one time postal service customers resulting in greatly reduced demand for first class mail, and competition for the remaining business by commercial shippers. Nonetheless, the postal service, while not technically a government agency has government ties. Any perceived inefficiency in handling of ballots is another reason to appeal election results in the courts.
Donald Trump has taken a wait and see attitude regarding the validity of election results. Hillary Clinton has suggested that Joe Biden not concede on election night should he apparently lose. Both sides in fact appear to be gearing up to challenge the election results. Being a federal election, either side losing at a lower federal appellate level will appeal to the next higher level federal court until, finally, they arrive at the Supreme Court. Barring a landslide, which won’t happen, both sides will determine rightly that they have everything to gain and nothing to lose by appealing to the very end.
So, the Supreme Court in 2020. The Court has a slight but real liberal bias at this time. Justices typically tend not to retire just prior to a presidential election, being aware that the current administration nominates a successor. If a conservative justice were to retire prior to the election the best a conservative administration could hope for is to maintain the status quo. If a liberal justice were to retire, they must be aware that they risk changing the balance of the Court at a politically delicate moment. Therefore it is safe to assume that there will not be a change in the makeup of the Court prior to the election.
My conclusion is that in a hotly contested election with not one but several potential legitimate causes for appeal to the courts, and with the final court of appeal being a slightly liberal leaning Supreme Court, this slightly liberal Supreme Court will ultimately decide the election. Conservatives have been shocked more than once to see Justice Roberts side with the liberal side in Court decisions. Given the vagaries of the arguments which will ultimately be presented to the Court, there are abundant opportunities to decide an election outcome according to political preference, thus the election outcome will ultimately be political, philosophical and most importantly, decided by a liberal leaning Supreme Court.
I am not political in the sense that I do not vote. I enjoy political science far too much to stake out a personal position in elections. For me it’s about the entertainment value; I have a philosophy degree, what can I tell you? As such I am not endorsing or supporting either candidate. This is not a political position; it is the joy of the journey there in my case. With that exception duly observed, and based on the above analysis, I am calling the election for Joe Biden as certified in the United States Supreme Court.
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
Attribution Dice (The Mobile Twist)
May 18, 2020
The one detail I will mention concerns an analyst whom, when asked about attribution for the cyber attack under investigation, produced a set of dice with various possible parties, methods and purposes printed thereon, and suggested that if the interviewer rolled the dice, the result would be as good a guess as the analyst or anyone else could probably provide.
Considering this argument, it makes a lot of sense. Suppose a French speaking hacker uses American Vault 7 code for his malware and for the purpose of obfuscation throws in some German comments or variable names, said code then analyzed by a Russian. In reality, this code could variously be attributed to or interpreted by a Frenchman, an African, a Canadian, a German, an American or a Russian, to say nothing of any of their respective governments. Or all of the clues could be red herrings.
I found this so amusing -and completely believable- that I decided I needed a set of attribution dice for my very own. Sadly, attribution dice are hard to find as physical items. They appear to be made by hand in small quantities, very much a niche item, and I was unable to find a set. Which left me the option of making a set of my own.
Given my personal areas of skill (and lack of same) if was far easier to take a picture and photoshop it, and create digital attribution dice than it would have been to create the physical item. Having made a decent Android app, it was a small step to make it available on Google Play.

Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
An Open Letter to US Bank (in the time of the Plague)
April 8, 2020
As you bask in abundant cell signal in Minneapolis, take a moment to consider rural America. There are vast swathes of the United States, now, in the year 2020, which have little or no cell signal. In a motivation near and dear to a banker's heart, it's not cost effective to put cell towers up in rural areas. The claims by many mobile carriers of high percentages of coverage are a marketing gimmick; in fact they cover this percentage of the population in high population density areas. And yet seniors and the disabled, living on fixed incomes, do not always live in these high density population areas, especially considering the increased cost of doing so.
I set up one of these seniors living in rural America with a rather powerful Android tablet, which she has learned to use. It has any and all of the features, functionality and power of an Android phone, except mobile signal. This is appropriate because there is no mobile signal available at her rural American home. It does have 5 GHz wifi, Google Play, a high end camera, in fact everything necessary to download and run your mobile banking app for Android, including remote deposit of checks. In order to enhance the device further, Google Voice was added for texting capability.
This senior had to risk coronavirus exposure for herself and her household which includes another senior and a disabled daughter in order to deposit a paper check even though the technology was available for her to avoid this risk. The only reason this dangerous excursion was necessary was that US Bank did not permit her to sign into the US Bank app because
- US Bank did not like the Google Voice number attached to the device
- US Bank would not even make an attempt to text the number offered
- US Bank did not offer an alternative method of verification such as email, postal mail or website login
To be clear, US Bank does not ever need to text anyone. US Bank may want to text customers, good marketing it may be, but good service and responsible corporate citizenship, especially during a pandemic, it is not.
Thank you for listening.
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
Masque of the Green Death, or, Those Old Coronavirus Blues
March 21, 2020
And Darkness and Decay and the Red Death held illimitable dominion over all. -- Edgar Allan Poe
The penthouse of Prince Prospectus was like no other. Well secured against the masses by private security, well stocked for a prolonged stay, and well populated by minions, entertaining, enterprising, and dependent to a man on the goodwill of Prince Prospectus, did they all retreat to wait while the Green Death burned itself out. And if the wait would be prolonged due in no small part to the initial reluctance of Prince Prospectus to shut down PRODUCTION, what of it? The wine was good, the food was excellent, and the Internet and merriment went on in the domain of Prince Prospectus.
A moment should be set aside to describe the penthouse of Prince Prospectus, for indeed it was a rare and unusual abode. The public rooms were seven in number, and each was decorated in a color after Prince Prospectus’ inclinations. Many were a shade of green, from the subtle gray green of a banknote, to the lusty green of a T-Bill coupon, to the bright neon green of a stock ticker. The last was gold, which is, in the end, the final fallback of worth after all fiat money has failed, or as some wags would have it, orange as a president’s hair, but never was such wit proclaimed in earshot of Prince Prospectus himself.
Now Prince Prospectus prepared a party as the peons raided the stores for toilet paper. To be sure Stephen King never wrote about a run on that particular item, but what of it? If anyone in Prince Prospectus’ circle was so crude as to have read Stephen King, it may be certain that they kept that fact very much to themselves. And the party!
How to describe such a party as Prince Prospectus threw! Everywhere was cliche. From somewhere, a minion had procured a gi, and he was Kung Flu! There were surgeons general and wandering attorneys assuring all and loudly, that there was no liability leg to stand upon!
But whenever the stock ticker in the neon green room chimed to indicate that another hundred points had been lost in the markets, the revelers paused, their hands reflexively crept to their belts, where their mobiles reported the damage. And, after calculating the damage to their portfolios, and that of Prince Prospectus, their mobiles were put away, and the revelers glanced at one another, some altogether a delicate shade of green Prince Prospectus has not provided, and they promised themselves that the next time the stock ticker chimed its doleful message that there would be no such pause, and yet, at the next chime, hands would creep toward mobiles once again.
Now there walked through the fete of Prince Prospectus a guest whose countenance was completely obscured. Dressed in surgical green, another color that Prince Prospectus had never considered for his decor, this apparition was, and it cast quite a pall upon the revelers. When Prince Prospectus saw this reveler he was seen to pale momentarily, but Prince Prospectus was a doughty man of business, and such surety surely defined him in his own domain as well.
Well did Prince Prospectus know that forward looking statements were no guarantee of future performance! Yet the apparition in the unusual green garb was, well, disturbing. Tacky, declasse, positively inappropriate to the occasion. Thus did Prince Prospectus order the apparition seized that he may be unmasked, and given a stern talking to regarding class, taste, refinement, and the subtle but real fatality of taking a joke too far!
But the apparition was not seized. All backed away in fear of the surgical habiliments, the rubber gloves, the masked face. Prince Prospectus, seeing both the reluctance of his minions, and the source of their discomfiture, decided on the spot that the so-tasteless minion bore more than a talking to. Prince Prospectus would, by gosh, FIRE the man. And with no reference! Such discordance as the low humor displayed was enough to put one off one’s game!
Yet, at first, there were none in all of Prince Prospectus’ retinue who would seize the ill-conceived jokester. Loyalty, Prince Prospectus realized suddenly in a moment of nearly paralyzing revelation, went so far and no further, and the more intelligent the minion, the more true this would be! Still, loyalty existed, in the lowly of the low, and Prince Prospectus’ chauffeur now leapt forward, loyal to Prince Prospectus in precisely the way that Prince Prospectus was not!
As the chauffeur seized the surgical garbed figure, he struggled, not with a man, but with the collapsing clothing which held no mortal form at all! And as the clothing fell into a disorganized pile upon the floor, the chauffeur began coughing. Prince Prospectus began coughing. The retinue began coughing. Could it be...it COULD be, that a natural microorganism would be so disrespectful, so UNCOUTH, yes! as to have no respect for class boundaries! It could happen; it was happening now!
And Darkness and Decay and the Green Death held illimitable dominion over all.
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
Quoth the Maven, Nevermore
July 4, 2017
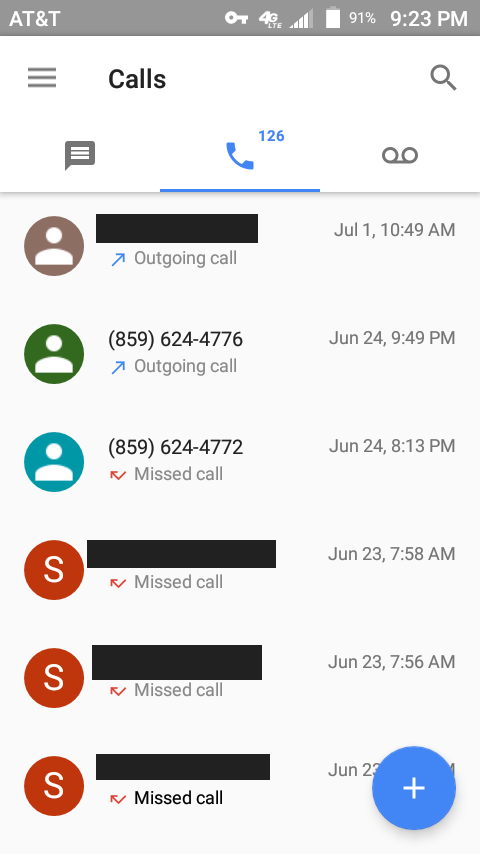
This injury comes as a result of a poorly designed mobile phone; poorly designed in the sense that more than one function which should not be activating by itself does so. The results escalate from nuisance harassment of emergency services to actual user injury.
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
June 27, 2017
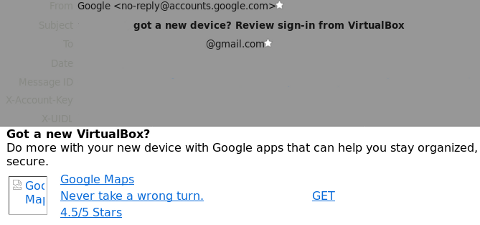
The forecast for big data is cloudy with a chance of GIGO.
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
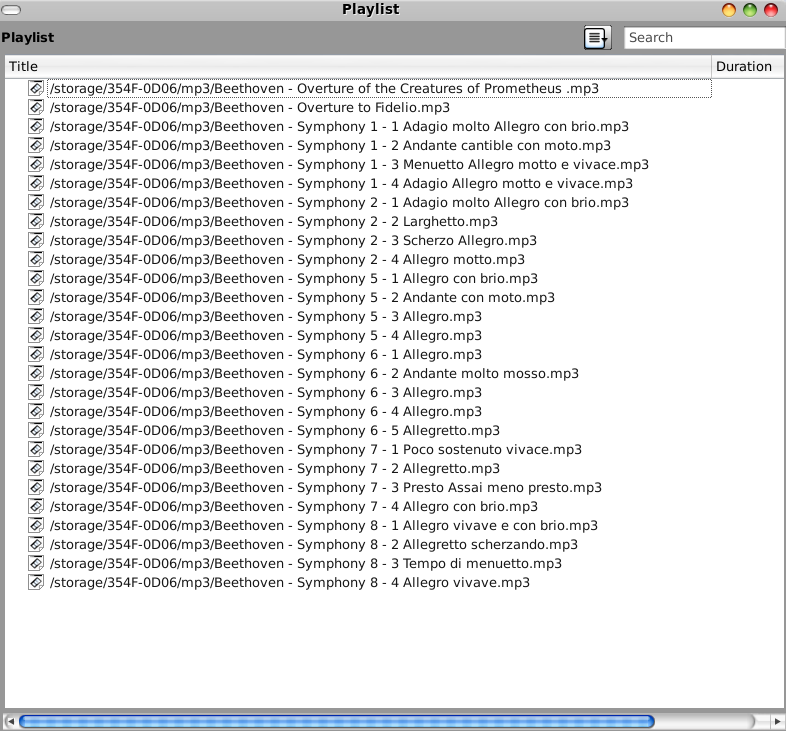
Marshmallow's Terrible, Horrible, No Good, Very Bad MP3 Player
January 14, 2017
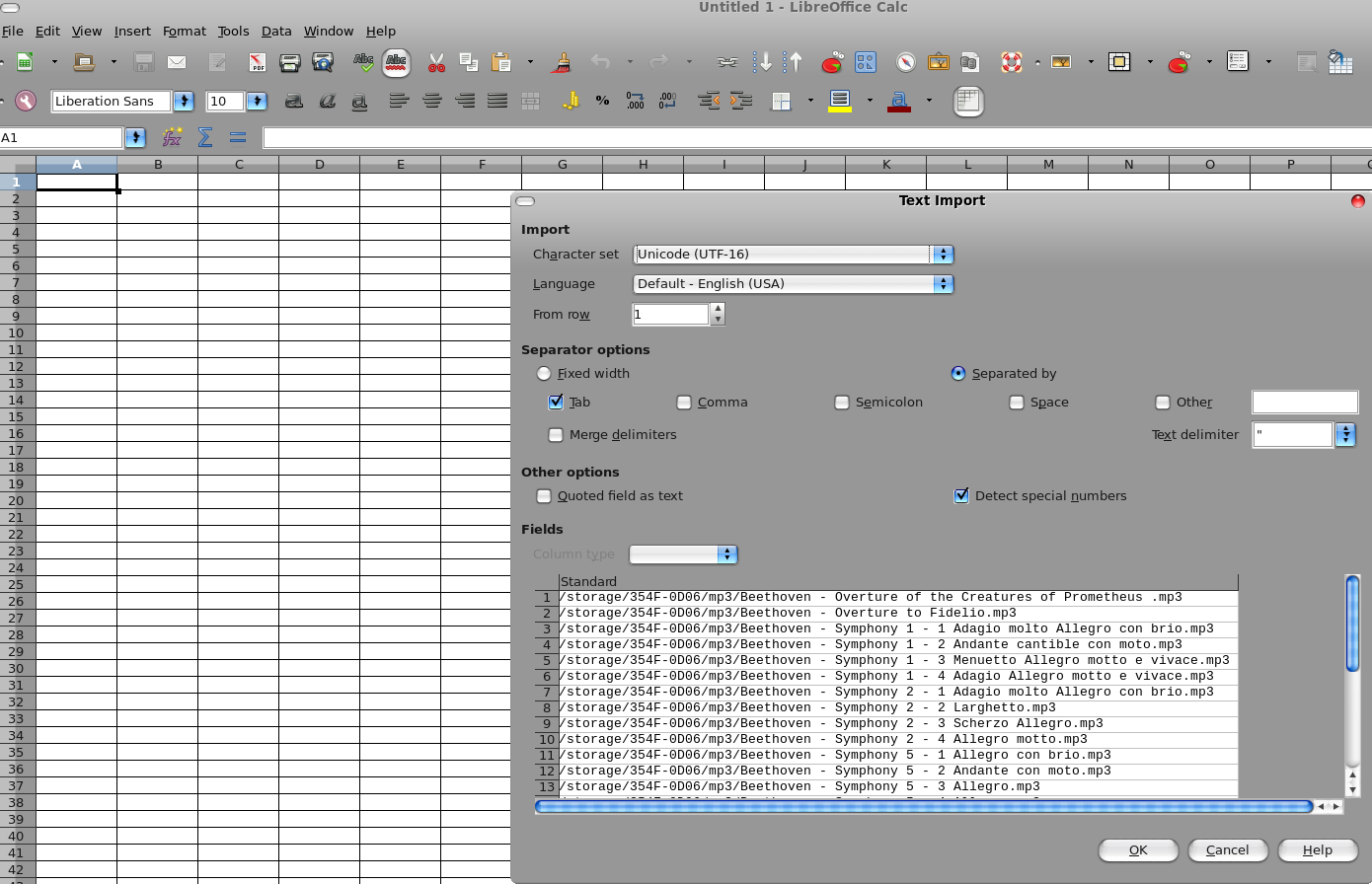
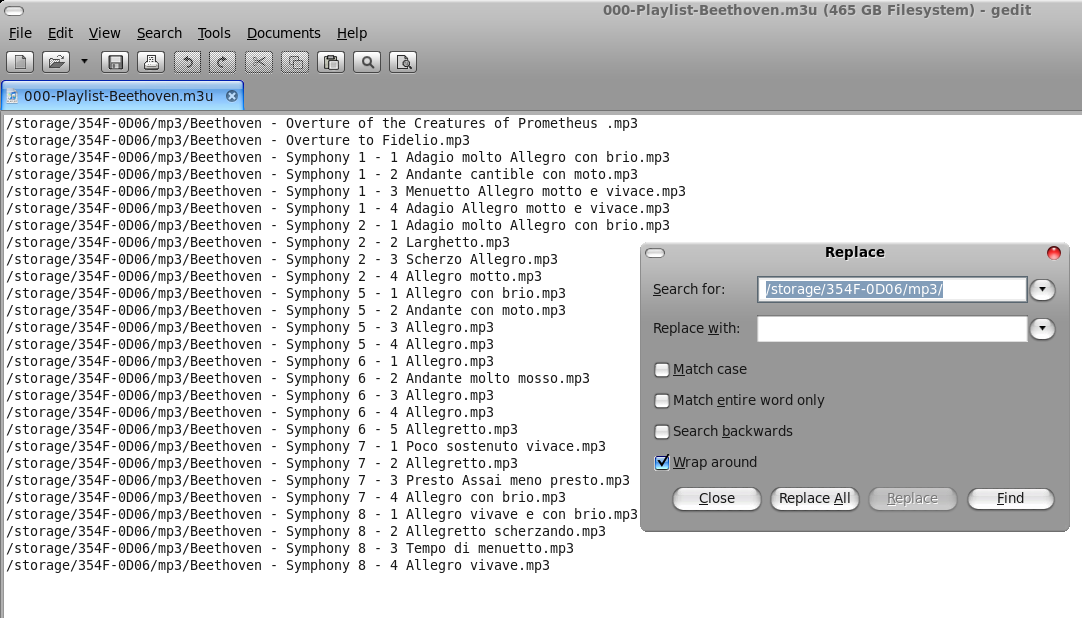
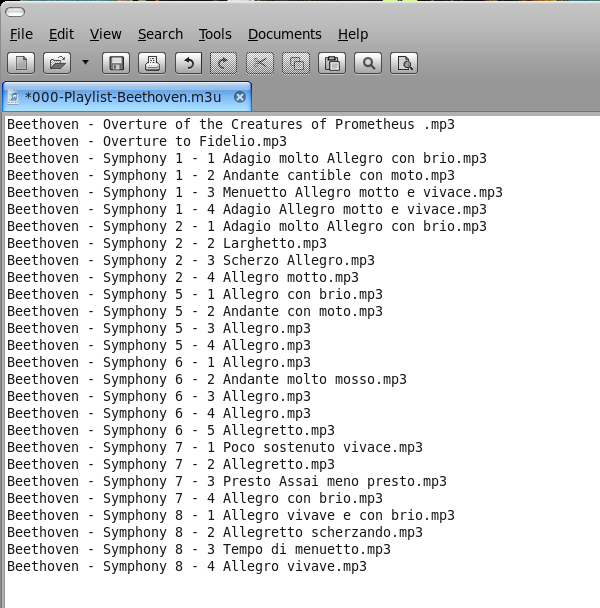
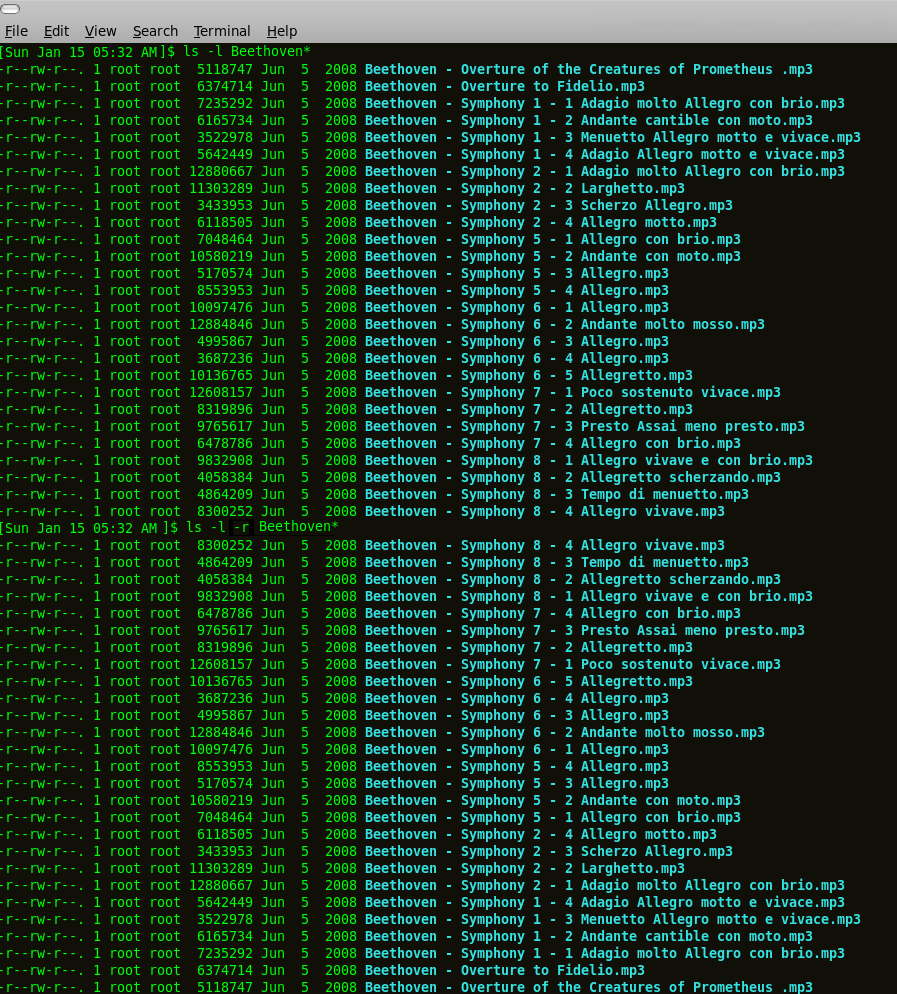
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
The (other) CSI Effect
January 4, 2016
Well, we can discuss it, but it's never going to be as fast as the computers on CSI, and it's going to cost you.
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
HOWTO: S/MIME Setup in Thunderbird
January 1, 2016
- Comodo (the CA) generates certificates for digital signatures and encryption of email
- CA sends a link via email in order for the end user to retrieve their certificates
- Browser gets the certificates from CA
- Browser installs the certificates to itself
- User asks browser to export certificates to user's computer
- User imports certificates into Thunderbird

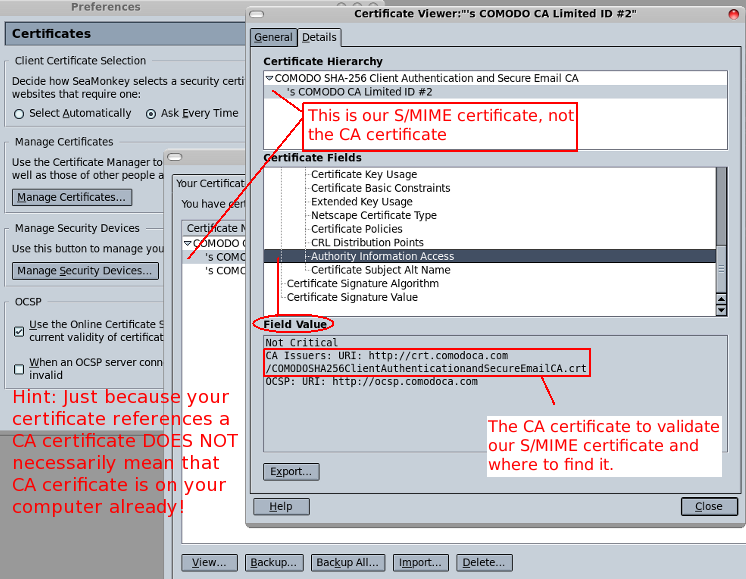
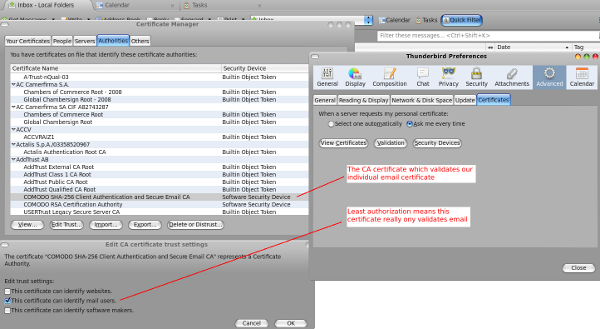
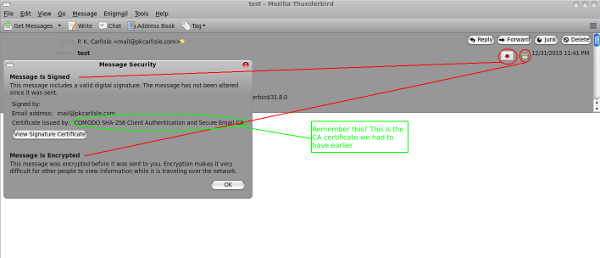
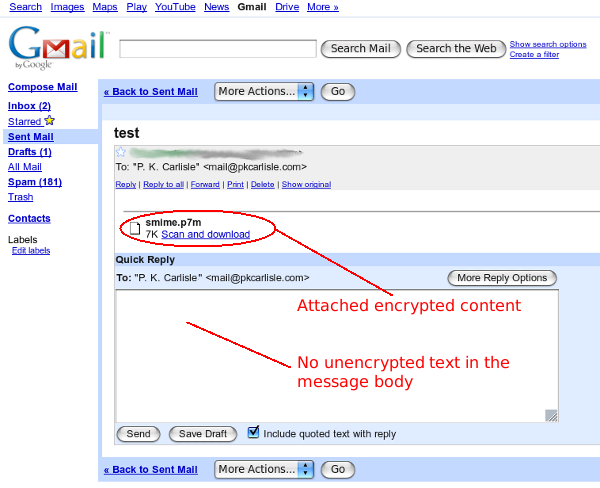
That's it, you're done. You should now be able to digitally sign and encrypt email with S/MIME in Thunderbird.
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
December 31, 2015
Best of luck with your exams.
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
Bedtime story for a puppy
September 27, 2015
(As told to my friend's new puppy)
Once upon a time...
There was a restaurant owner named Mister Vinh. Mister Vinh ran a Vietnamese restaurant, and his delighted customers would come from miles around to exclaim and marvel at the meat he served. “Mister Vinh, I don't know how you do it! I have never had meat like that before!” they would exclaim. Mister Vinh would nod and beam.
Now some say that Mister Vinh had his own idea of 'puppy chow'. Others say that's nonsense. Mister Vinh's is a puppy paradise, they say. Why, when puppies go to dinner with Mister Vinh, they like it there so much that they don't even come home. Ever. Again.
So be a good puppy and stop pooping in the hallway, because if Mister Vinh hears that you're a BAD puppy, he just may send a dinner invitation for YOU!
The End
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
Where ideas come from (and where they go)
September 26, 2015
Very often in life we act and think as we do because we are following conditioned behaviors. Uninterrupted, we will continue to follow this conditioning from cradle to grave without ever stopping to consider whether there is another, better way. Often it takes a catastrophe to jolt us out of our way of thinking and make us consider such ideas as free will, and responsibility to ourselves, and to the planet, and to future generations. But you can change your life without having disaster strike, and maybe in the bargain avoid disaster in the first place.
Mickey Spillane wrote his first Mike Hammer novel in 1947. Times, values and beliefs were different. The 1940's Hammer drank whiskey from the bottle, smoked unfiltered Luckies and food was whatever he could toss into a frying pan. About one in four Americans of that and later generations would still die from heart disease or other diet or lifestyle related problems, but the data hadn't been convincingly collated at that time, and people in general had not yet made the necessary mental connections.
Fast forward to 1989, and Mike Hammer was a reformed smoker and lite beer drinker who minded his diet and worked out in the health club. This change probably reflected Spillane's own health awakening, but it also illustrates the importance of a little perception and perspective.
What is perceived as normal is normal today. It may not have been normal yesterday and will not necessarily be normal tomorrow. A hundred years ago the pseudoscience of phrenology said that you could determine personality and abilities by the shape of someone's head. A hundred years from now people of today may be perceived as being frighteningly primitive to accept either twenty-five percent mortality from heart disease or a lifestyle in which bad habits are offset and cobbled together by every type of prescription imaginable.
It is possible for one person to change their own behavior within their own lifetime. To some degree, social norms will help, for example the negative attention tobacco use receives today as opposed to forty years ago. But you cannot and should not rely on changing social norms to define your reality for you.
Entirely too often social norms are dictated by corporate or political entities which may not have your best interest at heart. Who would have thought that the expanded awareness that many of the wholly avoidable medical ills which befall Americans would be answered by a slew of pills as a lifestyle augmentation? Would it not have been expected that such an awareness would have led to changing habits instead? Unfortunately, that did not happen, but there's a lesson to be learned nonetheless, and that lesson is that only you must be the final arbiter of which social norms you believe and follow.
The philosopher David Hume argued that there may be no such thing as free will. It's a tricky proposition because, if Hume is to be believed, everything that we know and believe is a combination or extension of what we already are or know or have experienced. Even the pursuit of knowledge itself is not exempt from this reasoning. So that, if one is conditioned to believe what they are passively taught, to go along to get along, that social and political systems will always work for the greater good, then it follows that these people will be unlikely to question the status quo or to accept responsibility for their life as they know it (unless their conditioning tells them that they are responsible, of course, in which case they go straight down Alice's rabbit hole trying to make sense of the logical inconsistency).
If current social norms trend toward conformity, this leads to a flawed model in which people go to one or another extreme, of either following social norms and denying that own actions and lifestyle in any way are responsible for any resulting discomfort, or accepting that something is wrong somewhere, but desperately seeking something, anything, to blame as long as it absolves them from any need to personally take dramatic action to improve themselves. Of course, neither extreme being a particularly good choice, many people spend an inordinate amount of time trying to make sense of what society tells them steadfastly must be true, even while common sense whispers that there's something wrong with the reasoning. The worst thing of all about where this reasoning leads is that you cannot reasonably expect to change this behavior for all or even most people who accept such conditioning.
The good news is that you can change your behavior for yourself and at least hope to impact what constitutes knowledge for those you care about. The very fact that you are reading this is information. Even if David Hume was correct and we are and can only be a product of existing knowledge and experience, now that you are aware of it, you have a responsibility to yourself to expose yourself to as much knowledge as you can, in order to become the most well rounded person that you are capable of being.
Of course, it really goes without saying that you are also volunteering to be an outsider to the degree that you think for yourself, and when that thinking leads to choices outside of the mainstream. That in itself is not a bad way to live, but it is worth mentioning if for no other reason than when you first experience any such social ostracization, you really have two choices to address it: to reassess your actions and decide that they are correct after all, or to scurry back to a safe level of social acceptability and like Shel Silverstein's Giving Tree, be happy (but not really).
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
It was a pleasure to tweet
August 30, 2015
It was a pleasure to tweet. And to text and to Facebook, too.
Read a book and you spend hours of your life, and it may not even end the way you would have it end. Hours you cannot get back and no guarantee of the result. But tweet or text! Why if it doesn't work out, you've spent 140 characters of time! Not satisfied? Send another. And again, and again. Sooner or later, your fingers move of their own accord. Autonomic tweets, automatic texts.
Nobody will read them, hell, nobody can possibly read them all. It doesn't matter, in fact, it's better that way. Cognitive dissonance. Believe that your tweets matter, know that they won't be read. Good feelings without responsibility. Why, responsibility itself is fourteen letters. It uses up a tenth of your tweet, just like that! Six syllables, ridiculous. Think of all you can fit into six syllables and fourteen letters if you don't waste 'em! Now! Wow! Click! Pic! Blink! Link!
Cursive writing isn't taught in school any more. Cursive comes from the same root as discursive, discursive means a flow of ideas, cursive is a flow of writing. Cursive only matters when there is a flow of words to communicate; who knows where that may lead! Learn the physical skill and you may use it. Develop ideas. Independently, how boring. To say nothing of unsocial. And how will you ever tweet them? You won't! You would have to write a book, and there you are tying up hours, stealing hours of someone's life, and you cannot even guarantee satisfaction.
Censorship isn't real. You learned that in school. “Censorship', 'government', 'bad'. There was a test. Say the words. Pass the test. You're educated. If it is not done by a government, it cannot be censorship. Does not 'censorship' mean 'government' plus 'bad'? When the news is censored by the news sellers, why it can be anything at all! Restraint. Protection. Good taste! As long as it fits into 140 characters. Blast! Passed! Past!
Here's a secret. Back when people read and thought, they didn't necessarily learn. Uncle Tom's Cabin: People do what they will and organized religion, depending on those same people for funding justifies from the pulpit what people wanted to do anyway. A hundred and fifty years ago, and still today my God can beat up your God. The only thing worse than no knowledge is nobody learning. The only thing worse than nobody learning is when you learn alone and shout into the wind and nobody hears you. Don't learn. It's painful and frustrating. Tweet! It's neat! It can't be beat!
People with computers want to sell you things. Other people with computers want to keep you safe. Doesn't work if we're not all the same. Make everyone the same. Reduce ideas to cliches, communication to a handful of letters. If nobody knows where ideas lead, they are blank slates waiting to be told. Don't tell them too much. They're not equipped and not interested. Easy! Breezy! Pleased!
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
Mark Twain and Google
July 28, 2015
Re-reading Huckleberry Finn, and never having actually precisely clarified the matter before, I decided to look up Jackson's Island to see exactly where it is on a map.
In the old days this would have to wait until I had a map or atlas available of sufficient scale as to show detail such as a small island; these days one can look at Google Maps and get a map on the same device as the book (hence my curiosity to precisely locate the landmark)...
...A map covered in a red banner with Google complaining about my tablet configuration and inviting me to start jumping through hoops (downloads, privacy policies, and the like) to see a map until it was quicker and less painful simply to give up.
Mark Twain would be perhaps unsurprised to note that human bureaucracy and confusion is keeping pace with technological progress quite nicely. Thank you, Google, for that confirmation of human nature.
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
Bitcoin: Observations and Thoughts
June 6, 2015
I recently had the opportunity to observe and consider some of the elements involved in the acquisition and use of Bitcoin (BTC). Other than the relatively minor positive element that using Bitcoin makes one appear to be a technical wizard with a depth of obscure knowledge, there did not appear to be much if any serious benefit to Bitcoin. From the perspective of people experienced with using, moving, and accounting for money in the real world, it's nothing new, and in some ways a lot worse. Quite possibly, that's even the point: If you are working with someone with their head in the technological cloud, they are probably less experienced with the more subtle points of money and accounting, making them comparatively more attractive targets. What follows are some of the actual elements observed.
Upwards of 40% in fees. Euphemize it, slant it, blame one party or another for fees, the reality is this: Converting US dollars to BTC and then spending them came with an average of more than 40% in fees. The euphemism chosen is irrelevant. If a credit card charged 42% to use it for purchases in another currency, how long would you continue to use it? What is paid to use a thing, no matter how the cost is categorized, is the rational basis for measurement.
Some paranoia required. It was necessary to play a drawn out cloak and dagger game, including use of once-off ciphers, and sending selfies holding identification documents to complete a BTC purchase. For a currency which is touted to be fringe and counter culture, it was a Byzantine identification process, ironically requiring identification issued by the very governments Bitcoin users by and large claim to distrust. Also, some less savory people hailing from a variety of (principally) eastern European countries fairly regularly recruit in, or come to the US and western Europe to engage in, a variety of credit card and banking fraud, siphon off a little or a lot of money, and scurry back home. Sending identification copies to the wrong person may well give whomever purchases it somewhere down the line what John Le Carre called a legend, a convenient identification to adopt on these forays.
Even once you have Bitcoin it's not anonymous. Virtually everyone who moves Bitcoin takes a slice of every transaction as a fee. Most often this process is automated, and must be in order to be practically applied. Consequently, often the Bitcoin address receiving the fee is well known (and would be, being hard coded into whatever software wallet's algorithm slices the fee off of each transaction). If you know a) the customary address or addresses receiving transfer fees, b) the amount of the fee, c) the customary fee percentage, and d) the time stamp of the fee, then it becomes a straightforward task to e) calculate the original transaction amount, f) inspect the block chain for that transaction, and g) track the transaction from start to finish. Not only can accountants do this easily, they actually like doing that sort of thing, it's their meat and drink.
[Lest there should be any lingering question about anonymity and Bitcoin, MultiBit, a popular Bitcoin wallet, appears to say a big "hello!" to a server shared with the New Zealand government when MultiBit is installed. New Zealand, being one of the so-called Five Eyes, even installing a Bitcoin client would seem to be grounds for surveillance, and Bitcoin users might consider themselves officially on a list. This is a screen capture from a Wireshark session run while installing MultiBit.]
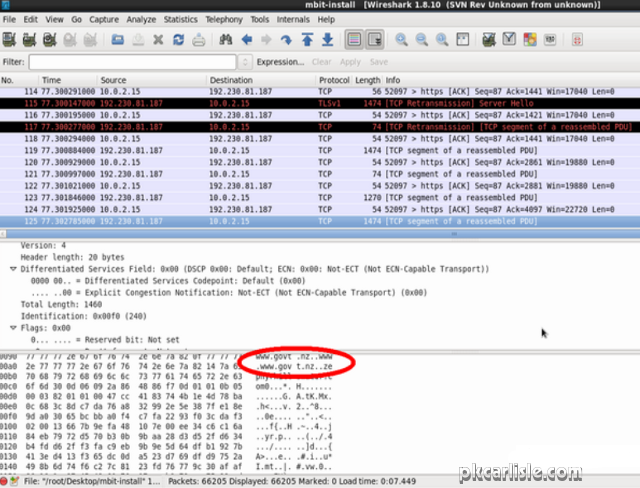
Not everyone cares about the anonymity of Bitcoin. To some it just seems a cool, techie thing to do. It's a fair descriptor, but at a 42% markup, Bitcoin had better be extraordinarily cool and techie. Also, with the identification process, it's fundamentally no different than using Paypal (and a lot more drawn out, dangerous, and expensive).
Bitcoin faucets today are largely confidence games. The Bitcoin faucet was originally conceived to get people to consider Bitcoin, and painlessly try it out without investing their own money. That concept has evolved into myriad sites which claim to pay fractions of a bitcoin for playing games, completing surveys, watching promotional videos, etc. There are several issues with the modern Bitcoin faucet which, cumulatively, may permit them to be safely classified largely as scams.
A bitcoin may be divided into thousands or millions of units. A faucet will pay a couple millionths of a bitcoin for completing a survey, watching a video or participating in whatever service it purveys. However, when you convert millionths of a bitcoin into, for example, US dollars, that comes to fractions of a penny for each video watched, survey completed, etc. That's a fair deal if you go into it with your eyes open. However, many faucets also have a minimum withdrawal limit on balances, meaning that for practical purposes, a user may have to spend an inconvenient number of weeks or months watching videos and completing surveys to acquire the minimum balance for withdrawal, which at that time may convert to a dollar or so.
If that isn't enough to discourage most users from sticking around long enough to actually collect, most faucets viewed pay bitcoin into their own proprietary wallets. Bitcoin is designed to not require this, which in turn indicates that this is intentionally added convolution which avoids what should be a fairly straightforward payment process. In short, bitcoin faucets appear to require considerable user interaction, while at the same time making an extraordinary effort to avoid paying amounts calculable in pennies. [In fairness, there was one site viewed which actually did, quickly and without qualm, send the .000457 BTC ($0.11 US) promised for the hour of surveys completed, videos watched, etc.]
In summary, at best Bitcoin is average or slightly below average in performance. Fees can be reasonably classified as excessive in many cases, meaning that there are significantly less expensive payment methods. Bitcoin does offer a cachet of technical savvy, perhaps offset by a perception of naivete about the real world. Anonymity is a myth to anyone who understands accounting. Scams and, to some degree justifiable, paranoia attach to it. Bitcoin would not seem to be a serious competitive currency.
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
Coming Soon: Goatcam!
May 12, 2015
I never imagined that I'd see myself writing this, but yes, Goatcam! is coming soon. I have a friend who started with a goat and added a variety of other farm-type animals to the menagerie, and I thought it would be an interesting technological challenge to set up Goatcam! to monitor it all live. The technical constraints made it interesting for me: it had to be free or nearly so, since Goatcam! is a fun project and not a serious commercial endeavor. That meant that it had to use existing or repurposed equipment and free or existing web services exclusively.
Goatcam! uses an old (now repurposed) Android device running over wifi. The Android device can use an app called IP Webcam (or IP Webcam Pro), which has various useful qualities including a comprehensive configuration interface, persistence on device reboots, local network wifi presence, and the ability to generate a still picture. The picture is processed on the back end in Linux, then sent to a Picasa album which is embedded in Goatcam! as a slideshow. This meets the needs of functionality (low bandwidth for a residential internet connection uploading content to a free service) and price point (in this case, nothing). A surprisingly consistent tendency among the non-technical is the belief that this sort of thing is, as a rule, free (it is, as a rule, not free). Being based on free products and services, I cannot guarantee permanency, but it will/does work now.
The technical side is essentially completed and is going through some final testing and adjustments. There are a few logistical details to be resolved both on the technical side, and on the, well, goat side. After that Goatcam! will be on the web. Watch this space for a link when it goes live!
Update: Goatcam! has had a minor setback in the timetable to going live, and is especially in need of a donated older Android device. If you have an older Android device sitting around and are willing to donate it to the cause, please contact me with the Contact link below. The Android device needed does not have very high requirements at all, but it does need the following minimum requirements to be useful:
- Phone or tablet, either is usable provided it can boot in wifi only mode
- Recent enough hardware/Android version to support video recording
- Video camera / video recording capability
- Bare minimum SD card (2 or 4GB), just enough to make any video configuration run smoothly
- No other advanced features required (the donated Android device will be dedicated to Goatcam!)
- Technically stable (no tendency to reboot, power off or lose charge spontaneously)
- Power cord required (the Android device will not be used unplugged)
If you have such a device laying about, don't know what to do with it, and are willing to donate it to the cause, please let me know. Goatcam! will thank you!
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
Windows: Then and Now
April 17, 2015
Short post today. I was on Windows 7 earlier and it brought to mind a little joke from the Windows 95/98 days.
It seems there was a man flying a plane, he's almost out of fuel and has to land right away, but he can't find the airport. He sees a large office building, so he writes a note which reads “WHERE AM I?”, sticks it against the window and flies low past the office building. He loops around and flies past again and the office workers have written “YOU ARE IN A PLANE AT LOW ALTITUDE FLYING PAST OUR BUILDING.” Then the man knew he was at Microsoft and could find the airport from there.
The more things change...
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
Fun in the Sun: A Solar Powered Laptop
April 01, 2015
It's that time of year when the snow melts, Spring has sprung and people take themselves back outside after the long hibernation. In that spirit, here's an easy to build solar powered laptop charger designed to keep you computing when you're out and about.
Enjoy!
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
LAMP, the Linux and Everything
March 26, 2015
LAMP (Linux, Apache, MySQL, PHP) operates as a bundle. There are exceptions to be sure, Linux can be replaced by Windows or Mac. But if you want what would be considered a 'clean' install for development, LAMP with a Linux is the way it's spelled. I recently set up a LAMP stack, and this post is a response to that experience.
In fact, this post is a little bit of a rantlet, a small rant. Several problems were wholly avoidable and lay squarely at the feet of various Linux distros. My problem was that I had faith for too long and kept trying to make work what can only be described as a kludge. When I gave up on that approach, I had LAMP up and running in no time.
- All attempts were done in virtual machines (VM). This is not a bad idea if you do not have requirements which prevent it, and in fact should cause no problems as a rule. The host OS in all cases was CentOS 6 64-bit. The VM environment was VirtualBox.
- First I tried Fedora 20 (“Captain Comic Book”). I nicknamed it that since it seems to have veered toward something which is glossy, light, locks users out of things the OS feels users should not be accessing, and is generally inconvenient to use and no longer a serious Linux distro. Add to this limitation a peculiarity of certain Linux purists: that if the packagers feel that the 'true open source purity' of a piece of software is somehow compromised by a logo or license or corporate entanglement, that software may not be included in their Linux distribution in its original form.
This was the case with MySQL in Captain Comic Book. MySQL is apparently insufficiently pure to be included in the distro, and has been replaced (poorly) by something called maria. This replacement is poor in that it uses (some but not all) different folder names and file locations for some files, installed into a distro which would prefer that poor dumb users not access the system level files at all (and manifests that preference by making it awfully difficult and roundabout to do so).
Add to that what is in fact probably a bug in MySQL and not a Fedora issue: There are, at last count roughly 42,000 Google hits for a certain MySQL install error in a variety of Linux MySQL installations. Captain Comic Book did not cause this error, but it is fair to say that between its new philosophy of inaccessibility and purist hissy fits, Fedora 20 definitely exacerbated the problem significantly. After probably a total of 24 hours (on and off over the course of a week) trying to work around these limits, I dumped the Fedora 20 VM entirely and moved on.
- Next I tried Ubuntu 12.04 LTS. No, it's not the 'latest' version. But that LTS label stands for long term support and Ubuntu was up to date. That didn't bother me; what concerned me is that Ubuntu has also gone the way of dumbed-down Linux (although Ubuntu has always tended toward dumbed-down by default, so it wasn't as long a trip in Ubuntu's case). This time I only dedicated a couple of hours to attempting LAMP in this environment. In the end, the limitations of dumbed-down Linux (Gnome 3, fighting against access limitations even an alternate GUI cannot overcome, and the same MySQL error which essentially requires system level access to a degree Ubuntu resists) were too great to overcome. As with Fedora 20, Ubuntu also did not cause the MySQL error, but Ubuntu did render it essentially not resolvable.
- Last I tried CentOS 6 32-bit in a customized, stripped down developer-oriented VM. MySQL popped the same error as in Fedora 20 (“Captain Comic Book”) and Ubuntu. Fine, I had pretty much decided that the error was a MySQL issue in any case. However, here's the difference. CentOS has not messed around with folder names; MySQL is still MySQL. CentOS has not messed around with accessibility; root access is still root access. Therefore while MySQL installed in CentOS experienced the same exact error as with the other distros, I was able to fix it in around five minutes. Literally. Five minutes, and move on.
A couple of hours without a Linux distro resisting every inch of the way and the LAMP stack is customized and ready to work.
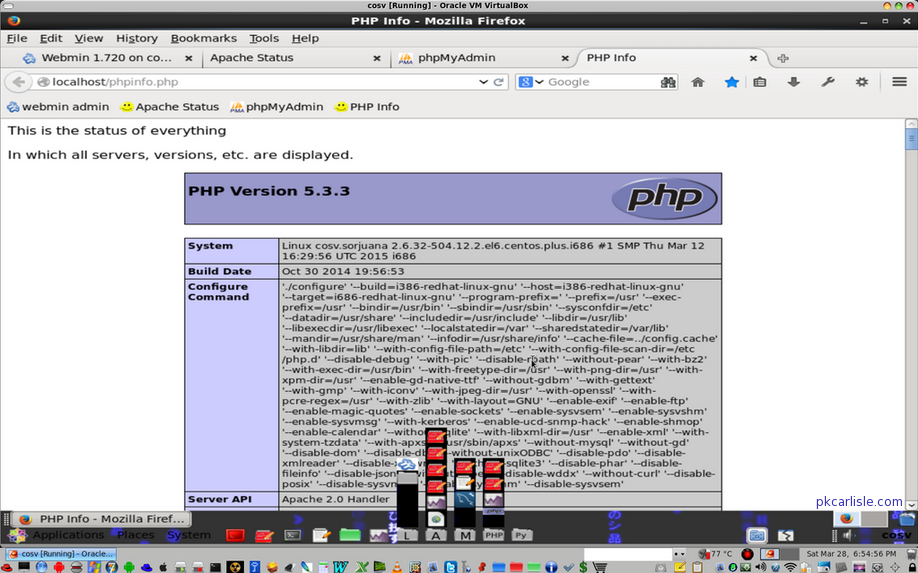
As I noted, LAMP (Linux, Apache, MySQL, PHP) operates as a bundle. If one component does not work as needed, none of it works. When the M has an error it does not matter what the cause is. If the L prevents fixing the M, the A and the P might as well not be there at all. Various dumbed-down Linux flavors are shooting themselves in the foot by rendering entire bundles like LAMP inoperative. That should be seen as a caution to those distro developers. It should also be seen as a caution to CentOS on where not to go as Gnome 2 support approaches end of life.
Closing thought. When making a complex construction like a LAMP stack, backing it up is like the Chicago ward boss said about voting: you can never do it too many times.

(Through 3 May 2015, the LAMP stack virtual machine is available at Amazon and eBay.)
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
A Dollar Donated via PayPal
March 14, 2015
A dollar donated via PayPal may possibly be a dollar lost.
Today's post is dedicated to all of those people who have provided exceptional content online, ask to get a small amount of recompense, deserve to receive it, and possibly never will. I have seen software applications, WordPress plugins, Mozilla plugins and blogs offering high quality items essentially for free, with the request, not a demand, that the user may, at their option, donate a little something to the project developers. Given the quality of some of these offerings, the users are getting an excellent deal in exchange for an optional donation.
But there are a couple of problems with the model. First understand what PayPal will permit the developer (blogger, etc.) to do. The developer may:
- Sign up to receive donations via PayPal,
- Actually receive donations in a PayPal account
Here is what the developer may not be able to do:
- Get paid. That is, withdraw actual spendable money from the PayPal account. Here's why:
To receive actual money received as a donation through PayPal (that is, not to have money lodged in a PayPal account, but actually to withdraw it, put it in your pocket and spend it) the recipient of a 'donation' must:
- be a legal, proper charity according to government rules (for example a 501(c)(3) non profit), or,
- eventually get PayPal's approval regarding how 'donated' funds will be spent.
The problems with PayPal donations, then are these:
- I am willing to wager that the vast majority of small developers who create a small software application or write a blog are not registered with the government as charities. These developers equate a 'donation' with the equivalent of a virtual tip jar. PayPal does not necessarily define a 'donation' the same way, AND,
- I am willing to wager that the vast majority of small developers will not become aware of this difference in definitions until PayPal asks them to provide their charity registration documents or explain how their donation schema correlates with the concept of charitable fundraising.
Four points remain to be considered. What to do about it, whether small developers have been cheated, why it's set up that way, and why I am bothering to write this up on my blog.
- What to do about the structure of donations versus payment? If using PayPal as the payment mechanism, change your PayPal payment type and website to accept payments and not donations if you are not a charity or collecting donations with charitable intent. Sorry, that's the way that it's done unless you explicitly have the mechanism in place to receive charitable donations. If an 'Add to Cart' or 'Buy Now' logo strikes a small developer as too commercial for what the small developer sees as a virtual tip, PayPal does permit the small developer (now technically a merchant) to upload a different button image instead.
Also, test your work by paying yourself a dollar or whatever amount you charge for your excellent project. Make sure the transaction registers as a payment and that you can get the actual withdrawal completed. Remember, simply receiving the money at PayPal (or in any other online account anywhere) is essentially meaningless; no one can ever truly be said to have been paid until the check clears.
- Have small developers, bloggers and the like been cheated by requesting donations through a structure which they may be unable to collect from? Oddly enough, no. The definition and responsibilities of a proper charity and of those accepting 'donations' is clearly set out in PayPal's terms of service.[1] I'm guessing the reason that small developers miss the difference in definition is that they equate the mental model of the tip jar with 'donations' and never read the fine print.
- Why does PayPal set up their system this way? I haven't a clue. I cannot speak for PayPal, I am not affiliated with PayPal in any way and cannot speak to, nor would I even want to guess or assume anything at all about PayPal policies or practices or motivation. I am neither a lawyer nor an accountant. I cannot and do not give legal or financial advice. However, I have worked with investments in a bank, and I can say why a theoretical Banco Philly might set up such a system:
With a small developer getting a few dozen or couple of hundred dollars a year in 'donations' it will be long time before the small developer discovers that they were not supposed to accept 'donations'.
Also, once the small developers do discover a difference of definitions, there would be still more time during which Banco Philly would graciously wait for the small developer to provide legal paperwork or other evidence of charitable intent (which Banco Philly knows the small developer likely can never produce).
During all of this time, Banco Philly will earn interest income on the small developer's money that it's holding. By itself, that's pocket change, but interest on a hundred dollars here and a couple of hundred dollars there, times a few million accounts, plus the time Banco Philly graciously waits for the small developer to provide legal paperwork or other evidence of charitable intent (which Banco Philly knows the small developer likely can never produce), can add up to massive interest income for Banco Philly.
That's called the float, the time between which money is received and paid out. Earning interest on money held during the float is perfectly legitimate, and that's how and why Banco Philly would do it.
- Why am I bothering to blog about this subject? I continue to see to this day, a lot of sincerely superb projects on the internet for which PayPal 'donations' are requested. I use a couple of those projects long term and have used others only for obscure technical tasks. Elements which some of these truly exceptional projects have had in common are:
their undeniable excellence,
the fact that the small developers want a small consideration for truly excellent work,
the unfortunate request for a 'donation' instead of a payment on the small developer's site.
This last may mean a small developer patiently watching a donation balance grow, only to discover that requesting a 'donation' violated a clearly stated policy and that the developer may receive nothing for their efforts. This blog post is my 'donation' to small developers everywhere who may have picked the wrong category for their PayPal account, who set out the virtual tip jar expecting some small well deserved consideration for excellence.
For the gal who wrote the wallpaper, for the guy who wrote the plugin, and the other one who had that truly awesome tweak for VirtualBox, and who all had a 'donation' option on their pages, and for thousands like them, this one's for you.
[1] PayPal. Donation Buttons. Retrieved March 13, 2015. https://www.paypal.com/us/cgi-bin/?cmd=_donate-intro-outside.
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
Tweons: Horribly Helpless Twitter Peons
March 12, 2015
This is, well, not the story, but another chapter in why social media outlets self destruct. It's happened before, it will doubtless happen again. In that sense, the story does not have a beginning and an end. It just goes on and on...
Today's chapter is about a $30 billion company called Twitter. That's billion, with a B. For perspective, Twitter could buy a stealth bomber and not even miss the cost.
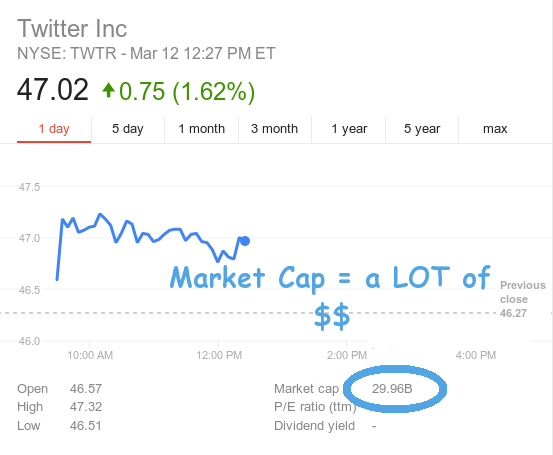
But Twitter, for all of its abundant dollars is helpless to assist its customers. They say it right here.
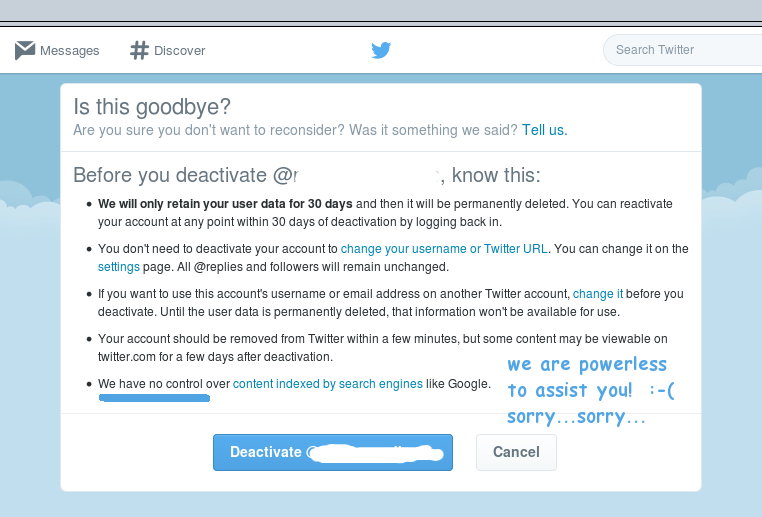
Yes, when it comes to allowing Google to post tweets as part of a Google search, Twitter appears to have fallen prey to that all too popular American business model, the helpless peon syndrome. Their options would be to make a meaningful effort to protect Twitter users and negotiate an opt out with Google, considerably more involved and a potentially expensive option, or to opt for policy by one-liner exemplified in the helpless peon syndrome: we can afford an air force larger than that of some countries, but “we have no control.”
A subtlety, an optional variant of the helpless peon syndrome, is to refer any customer you have no intention of helping to somewhere, anywhere, elsewhere as soon as possible. Blame anyone, everyone, someone else! One way Twitter leverages this subtlety is by linking to Google. Dealing with Google on a one-on-one basis is, as always, a difficult exercise (although they do have some relatively convincing bots responding to emails), but is also not really the point here. The point is the $30 billion company arguing a position of helplessness. Is that an argument you really want to win?
- To successfully argue helplessness is to argue helplessness.
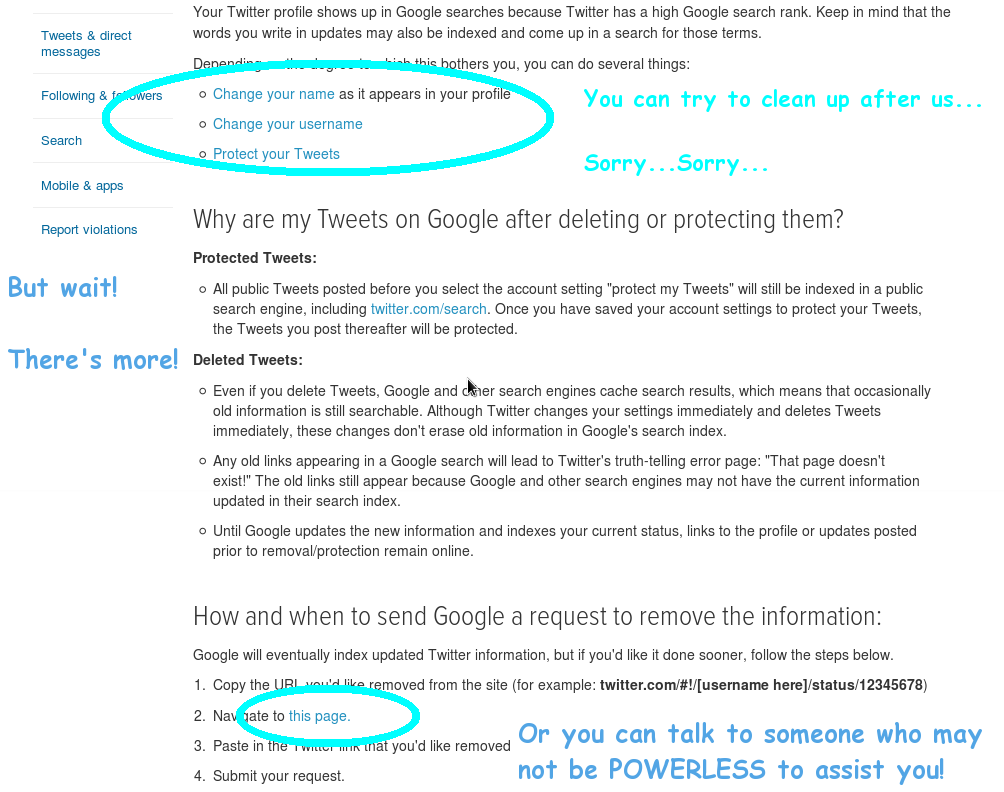
Another quite popular variant is to blame the user. Play Behind the Iron Curtain, says Twitter. Change your user name and hope that you cannot be linked to existing content. Twitter itself is powerless to assist you. The point is that when a multi-billion dollar company tells its customers how anyone, everyone, someone else is responsible, it says something fundamental about the company's values and sense of worth they hold for their customers.
One of the biggest problems with the helpless peon customer service model is the tempting immediate success and eventual failure inherent in the model. The helpless peon model succeeds in that it brings fast, fast, relief. Unhappy customers go away. However, customers go away unhappy, and that is the long term flaw in the model.
Twitter is no exception to the rule. The helpless peon policy successfully sends customers away, undoubtedly true, but it sends them away unhappy. It logically follows that built into that policy model is the assumption that it is acceptable to have unhappy customers. In the end, it matters not at all if Twitter is to blame or not, Twitter ultimately assumes the responsibility for unhappy customers. As Facebook and My Space may attest, a social network accepts an unhappy customer model at its long term peril.
- To successfully avoid helping unhappy customers requires unhappy customers.
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
WordPress Conversion - Episode III: A New Nope
March 9, 2015
Mail:
Mail. I got mail about the last blog post. Thought provoking comments, all. What the internet is supposed to be all about. I'll address some of the highlights here.
I got references to several SEO and monitor type tools. I have not assessed them yet, so I will not go into names of applications. For SEO and monitoring tools to be useful, it follows (or precedes, as is actually the case) that one must first develop a site worth deploying or monitoring. Since I have not produced anything in WordPress which would not make me cry for shame, deployment is out of the question at this point.
One response addressed my assertion that WordPress sites appeared 'cookie cutter' in appearance. I was working with WP theme Twentythirteen because it was so well commented, but tendency toward that theme may be the reason that WP sites overall seem to be so similar. I accept the reasoning, but that leads, in my opinion, to a conflict. If one theme tends to be a choice because it is well commented and therefore more readily comprehensible, how does one justify using a theme which is not well commented? Or does one even justify it at all? There were three tangents to the response which addressed the conundrum with (again, my opinion) varying degrees of efficacy.
The first option was to accept the cookie cutter appearance if the commenting of the theme was so important to the ability to design that it made a critical difference. I accept the logic, but personally feel that if the result is a similarity of sites to the degree that a non-WordPress user can visually identify WP sites, that might make WP a lot less attractive in the long term. Still, it's a working option, so, noted.
The next option was to learn WP and accept that code in WP templates will not be commented. The argument goes that comments in code must be loaded as a web site loads. Therefore the comments slow down the loading of the site every time that a comment exists. Also, real professionals do not comment code; in fact that's how to identify the code as the product of a professional. I have a couple of responses to these arguments.
State of the Code:
For one, I have done some coding, and I hate to comment it. It works as coded, so what's the problem? The problem is exactly what I am addressing in trying to work with WP templates. The developer designs the theme, hands it off to someone else (myself, the developer of the specific site) who in turn finds it difficult to use because the code is not commented. Without comments in the code, using the code which is handed off means that what should by all rights be a simple process becomes a bizarre ritual.
Sorry, we're going to have to agree to disagree on this one. If you code it, comment it. If you don't comment it, it logically would not and should not be used as often as well commented code, especially when a theme is designed to be a template, is designed with the explicit understanding that it is to be further modified. As for the argument about website load times increasing from having to load pages including full comments, I don't buy it. You can run Netflix inside of Firefox inside of Windows inside of VirtualBox inside of enterprise Linux and still watch a movie. A medium sized JPEG graphic is in the 25-50K range. Bandwidth, processing and memory are sufficient these days that loading 5 or even 10K of extra code which includes comments won't even be noticed.
And if the concern about comments remains, by all means, write a script to cleanse pages of comments when ready for deployment. But don't stick a template with 10,000+ lines of code online, 5% of which is commented, and wonder why it's not useful. Last but not least, there's the option used by Twentythirteen: name your theme's variables something rational compared to what the variables do. That lowers code which must be loaded on the user's browser and still leaves a usable theme for website developers.
The argument that commenting code is passe, that the need for code comments reflects the ignorance of the web site creator and not a fundamental flaw in the code itself is lovely, wholly, robustly, modern American. You have two choices: Comment your code properly (a lot of work), or, take offense that someone would be offended, tweet it thereby making it real, and go have a latte (a lot less work, and the choice 4 out of 5 Americans recommend most).
Meanwhile, here is the realistic state of the code comments: Thousands of blog entries exist, each addressing a particular snippet of code as someone discovered and resolved the effect of that single specific uncommented code snippet. The very fact that there are thousands of individual pages from thousands of individual users addressing thousands of individual code snippets should indicate that there is a fundamental flaw in the product, when thousands of separate pages exist in no rational order, essentially writing the documentation piecemeal which should properly exist in the first place.
You've Been Here Before:
I would like to pretend that I am not shouting into a hurricane with my observation, but I realize that I probably am. Take Linux and Python as examples. Both are lovely examples of what they do. Both have, to put it charitably, substandard docs (again, applying my definition: that tens of thousands of piecemeal blog entries dealing with heretofore undocumented or poorly documented functions, documented and posted independently by thousands of individual bloggers as they are discovered and figured out does not equal quality documentation).
WordPress is unfortunately technically in the same situation, and in fact the situation is worse. WP is every bit as poorly (but not necessarily more poorly) documented, true, but WP now has precedence. WP can say, 'Look at Linux, look at Python. Whomping out 10,000+ lines of uncommented code with cryptic variable names or poorly described functions is perfectly acceptable, it's the end user's fault, I'm offended that you do not see the Christlike perfection of the project, and that's a tall skim latte.'
WordPress Frameworks:
Another mail comment was to seek out a WordPress Framework. Being experimental at this point, I looked into free options. The comment which I received was along the lines that with such a tool, it would not even be necessary to touch code. Awesome. I looked for a Framework. Now I may be using them wrong, but these Frameworks are essentially just themes. They have a default appearance for your page (kind of a cross between Microsoft and a coloring book in appearance) and thousands of uncommented lines of code, documented piecemeal in thousands of blogs, etc., etc. In fairness, the framework/theme I have played with the most does add one (and only one) 'codeless' feature to the dashboard to disable the otherwise exceptionally well hidden “Proudly created in WordPress” blurb (which, by this point, is in itself no bad thing). Otherwise, the framework is just the same as any other theme: accept a cookie cutter design or stumble through thousands of undocumented lines, blah, blah, blah.
One Approach:
My approach to this attempt at WordPress conversion is to go into these themes and disable as many options as possible. Let's look at the options realistically.
Option 1:
- Spend 5-10 minutes Google searching various blog posts for how to do task a. Since these blog posts are volunteer efforts at documentation and narrowly tailored to resolving one specific problem in one specific version of one specific theme, maybe it is similar to what I am looking to adjust, maybe not. Dunno. So, read multiple blog posts.
- Spend five more minutes of my limited time on this planet figuring out which file the code snippet belongs in, edit and save the code.
- Reload web page to check results.
- If not successful, remove code changes and save code.
- Repeat Option 1. Possibly for hours.
Option 2:
- Rather than customizing (say, a menu), figure on removing it.
- Similar to Option 1 in operation, but generally requires fewer guesses, fails, reverts and subsequent searches. And hours.
The problem with Option 2 is of course, the WP theme becomes so limited in functionality that it may as well be HTML. All of the undocumented features are simply disabled. So why not simply do HTML and be done with it? I am not exactly sure why not, and that is the beginning of deciding that WordPress just may not be worth the bother. However, I'll keep plugging away at it awhile yet, not because I am sure at this point that WordPress has something to offer, but more as a matter of will.
To Be Continued:
As a closing thought for this episode, there is another factor which must honestly be considered regarding the utility of WordPress, especially with regard to disabling features. All too many of the newly revamped WordPress pages I am seeing use the WordPress equivalent of pop-ups. I'm not sure what the WP terminology is for these sliding, fading panels, and it's not really important at this point.
What is important, is that these are, label notwithstanding, pop-ups (of a variety which browser pop-up blockers have yet to block). So, then, the advanced WP features (and the reason that I should want to use WordPress?) is to enforce on my site the very annoyances which make me leave other websites when I encounter them? The annoyances which, in a different web technology model, have long since been addressed? It does not really matter whether it is labeled as a pop-up or a Persistent Interactive Sliding System Engaging Multiple Optional Fill-in Fields (PISSEMOFF) or a User Parameter Yielding Objective Usage Research Statistics (UPYOURS), it is a pop-up by any other name, and it is as annoying today as ever it was.
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
WordPress Conversion - Continued
February 25, 2015
I spent many hours getting to know quite a lot about WordPress, with an eye to converting pkcarlisle.com to that format. The following are some observations about that ongoing journey.
Documentation:
About like I suspected it would be. Abundant, but unstructured and ad hoc. A lot of people with a lot experience making their best educated guesses. And they were guesses. Sometimes one person would suggest hacking one system level configuration file, and somebody else would suggest another hack altogether. One or both of the suggestions would sometimes work, other times neither would work.
I found a free resource which, while short, was worth a quick read. There is a book on Google Play called WordPress in 12 Easy Steps which was a nice way to get my feet wet in WP. And you can't beat the low, low price of nothing.
There's also WordPress Codex, supposedly the ultimate WP how-to. Advantage, everything WordPress is at least referenced in there somewhere if not explained well. Disadvantage, the assumption behind the model is self contradictory. If one has multiple years of WP experience, one will not need basic documentation. If one does not have multiple years of WP experience, the Codex is not so very useful. (General rule of thumb: if someone has to tell you how easy their product is, it's probably not.)
I bought a motorcycle technical manual one time. I found out that I could not do most of the procedures in the manual. This was because most of the procedures outlined started with the same first instruction, to wit: Go into your well stocked professional auto mechanic's garage and put the bike on the lift. WP documentation is kind of like that, to wit: extending on your years of existing WP experience, this process is simple enough... This is similar to the style of open source documentation everywhere, and while it's always a bit disingenuous, in fairness it is not specifically a WP thing.
Apparent Philosophy of WordPress:
I thought about why people may want WordPress, what WP is and what it is not. WP reminded me of a line from the old M*A*S*H television series in which Larry Linville whined that being an individual was fine as long as everyone all did it together (pause for laughter). WP is much like that. It is a cookie cutter approach to web page creation, and all who use WP are all individuals...together. In fact, I only decided to sit down and bother to learn to use WP because I started seeing so many lookalike web sites which were obviously done in WP that I started to wonder what was happening.
Cookie cutter approach:
WordPress is essentially a cookie cutter model, but can it ever crank out the cookies fast. Advantage, quick to use once the template page is set up, disadvantage, someone else has largely decided what the limitations of the template will be, as a result lots of web sites end up with a suspicious lack of individuality. For example, I note that many sites created with WP retain the built in search bar/magnifying glass combination lurking somewhere even when the function is not used (try it on a few WP sites). However, it is coded into a lot of WP themes and difficult (but not impossible) to remove, so it's left there hanging uselessly like the appendix.
On the subject of cookie cutters and individualized pages, consider WP themes. In my case, I already have a website and content, and don't really want to start over from scratch. So a theme which would not easily permit incorporation or conversion of existing content would be less useful. Therefore, I made the assumption that for a conversion, the primary goal would be to remove elements from a cookie cutter template as much as or more than adding elements. This turned out to be true, and since it was true, a WP theme which facilitated that approach was preferred.
WordPress Themes:
A WordPress theme is a template. It has elements included in it by default, some of which may be removed or changed, and others which are resistant to removal or change. Once a theme is customized to taste (or customized as much as WP will allow and therefore settled for), it is fairly quick to copy/paste and save-as for each new page of a site. However, if each new page is ultimately unsatisfactory because the template has elements which are not easily removed or altered, the site as a whole is a little unsatisfactory. And that's a shame. I do not want to have that grungy feeling about my website.
The WP theme I recommend is called Twentythirteen. Just like that, one word. Twentythirteen is a bit limited in the sense that is does not have sliding panes by default or a lot of the visual bells and whistles people tend to associate with WordPress, but it has one major advantage: the variables are sanely named. With WP, realistically you have two options: accept the templates and plugins as provided and learn to live with the limitations (that grungy feeling), or get on your code hacking boots. Twentythirteen, as a WP theme, facilitates code hacking enough to be a major selling point.
Twentythirteen has style sheet code which looks kind of like this:
.site-header {
color: #000000;
display: none;
}
.site-header .search-form {
color: #000000;
display: none;
}
.site-footer {
color: #000000;
display: none;
}
Access to the code can be good or bad depending on individual ability, but either way, the functions of the above code are reasonably guessable, even to someone just starting out with WP code hacking. On the other hand, consider this code from another theme's style sheet:
/* logo and controls */
#colophon #wordpress-logo {
background: transparent url(images/wordpress-logo.png) no-repeat scroll 0 0 ;
bottom: 0;
height: 30px;
left: 220px;
overflow: hidden;
position: absolute;
text-indent: -999em;
width: 100px;
This sample is from a 1,500 line style sheet, and that's all you get for this function. This is the code which does a task and the comment which describes it. For 1,500 lines. Of one file. There are several other configuration files which may also need code hacking to get the expected result. All equally if not more poorly commented.
Since a WordPress creation will be done online, each code hack will take at least a minute to update a server so that you can reload the page and see the results of that hack. Hack, upload, repeat. Also, some code segments impact other code segments (What? That's not commented. No, it's not commented, but it's true.) With each code hack, style sheet update and page refresh taking even a couple of minutes, guessing how a few segments of poorly commented code interact with one another and customizing to taste can quickly expand to consume an inconvenient number of hours.
Twentythirteen, as a WP theme with meaningful variable names in the style sheet code, is much quicker to hack. If you are going to go the route of code hacking the style sheet to address the WP cookie cutter, adequate code comments or meaningful variable names is enough to drive a choice of themes. (Disclaimer: There are dozens if not hundreds of WordPress themes available, and I did not examine the code on more than a handful. If a WordPress user out there in cyberspace can identify a theme with a better named variable scheme or comments, please drop me an email.)
Backups:
I have said it before and I'll say it again. Back up early, back up often. If you are looking at major conversion (HTML to WordPress qualifies as major) make sure that you can put things back or wait to bring the new attempt online. WP will not harm existing HTML code or web pages, but somewhere along the line you may be tempted to copy/paste one thing or hack another thing 'just a little bit'. Back up early, back up often.
When doing a major conversion, don't assume that things will work out okay, assure it with appropriate backups. I use the schema ., .pop, .gpop and sometimes .ggpop (so I have blog.html, blog.html.pop, blog.html.gpop, and even sometimes blog.html.ggpop, respectively, the current active file, the father, the grandfather, and the great-grandfather versions). Use .html, .html.father, .html.son, .html.holyghost. It doesn't matter as long as the schema is consistent in naming. Have at least three generations of an absolutely crucial file. In case of disaster, everything can be put back. That's the point.

The same will go for your WordPress pages. Download and save your preferred theme in case you need to reinstall it. Back up any original configuration files before you start to code hack that file. Back up style sheets, especially before and after major or uncertain hacking of the code. (Can you give me a style.css.orig, and a style.css.pop? Amen, brother.) Without a backup, you are relying on someone else to not update your WP theme or software in a way you may not like. No one ever has your best interest at heart as much as you do.
Comments:
Comment, comment and comment some more. The WordPress style.css code sample
.site-header .search-form {
color: #000000;
display: none;
}
properly commented, should read
.site-header .search-form {
/* orig. color modded by pkc */
/* color: #FFFFFF */
color: #000000;
/* display: none added by pkc to temp. disable display of this item */
display: none;
}
Now I know what I modified each time (did you see that there are two code hacks there?) and why and how to put it back the way that it was. I also have working samples which I may use later for another code hack elsewhere. It's more work, but comment, comment, comment.
Next Steps:
If I go there, the next installment of this WordPress journal may be on the conversion of this blog to WP. It occurs to me that I have been writing on the subject of a WP conversion and I haven't converted anything to show. In fact, I did convert the main page of this site, but I was not really delighted with the result, and I feel that the original HTML is still better on several levels.
It is possible to mix HTML and WordPress pages on a site, in fact in some cases such a mix may be desirable. For the record, WP can create static pages (www.pkcarlisle.com/index.html is a relatively static page) as well as dynamic (rapidly updating) blogs. Greater flexibility may be more preferred on some static pages, while cookie cutter rapidity may be more desirable for a blog. So, if WP essentially says, here's your mandatory magnifying glass and search bar, everyone else has one and they don't use it either, so live with it, you may be justified in deciding that some pages on a site will merit WordPress' structured approach while other pages definitely will not.
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
WordPress Conversion - Prologue
February 23, 2015
I am labeling this section Prologue, because I strongly suspect that this post will extend significantly and have several tangents or potentialities. This first section will simply address intent. Specifically, my intention is to look at the option of converting pkcarlisle.com to WordPress. I am going into this cold, however, and I already see some significant issues with the process.
One issue is the contrast between quantity and quality which is all too often apparent in the documentation of not a few open source projects. In fairness, this contrast must be considered in light of the fact that the project is open source, and therefore largely supported by volunteer efforts. The reality is that coders code, and as a rule hate documentation. As a result, some of the best coders (WordPress or otherwise) do not contribute to existing documentation at all, or, when they do, they contribute ad hoc, they are not too concerned about editing or categorization, and if that reduces the utility of the documentation, one must be grateful that such documentation exists at all.
I will attempt to keep reasonable notes about the conversion process in an attempt to streamline the process. By streamline, I mean to reduce the vast quantity of documentation to arrive at something approaching quality. Of course, it must be noted that the items I see as quality may differ from the requirements of others. The exception is so noted.
Last but not least, this prologue exists as an advisory: any formatting irregularities or missing sections apparent on pkcarlisle.com in the next days, weeks, or months may be attributable to the conversion process.
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
Je Suis Charlie
January 7, 2015

On this date, three Islamic fundamentalists attacked the offices of a French satirical weekly called Charlie Hebdo and killed a dozen people in the name of their god. It is not necessary to go into details of the attack, there are plenty of resources to recount the gritty details. My French is at the level Agatha Christie called 'Shopping and Hotel', I can read it passably well, but not well enough to have been able to read CH on a regular basis. However, in fact I had read CH regularly for several years and was and still am a staunch supporter of satire.
Once there was a now defunct monthly magazine called National Lampoon. NL offended everybody equally. They took shots at Jews and Muslims, Christians, Catholics, gays, straights, the left, the right. They were an equal opportunity offender. And it was satire. To create effective satire, you must have an understanding of truth, and understand that yours is only one perspective. Truth as you see it, truth as the subject of the satire sees it, as society at large sees it, and how the differences between varying viewpoints leads to different courses of action, lifestyles, etc., and how those opposing perceptions of reality may come to collide in a democratic society. It's no coincidence that some of the best comedians were philosophy majors in college.
Somewhere in there, examining the different definitions of truth, you may be able to laugh. Somewhere in there you may learn something about others or even (this is where it gets complicated) the truth as you yourself see it. That's what good satire does: it examines truth for what is enduring truth, what the cliche, and whether people are motivated by understanding or conditioning, be it social, religious, educational or that of any other institution. Maybe as a result, you break out of your conditioned perspective and come to an individual conclusion and set of values. And that's called knowledge, that's called enlightenment, that's called philosophy.
So Muslims as a group have to suffer with a handful of extremists who cannot credibly express their beliefs in words and must resort to the machine gun. It makes you understand how Italians feel about the Mafia or Christians about Westboro Baptist Church, Catholics about the Inquisition or Jews about the Irgun. Maybe it's human nature: there is all too often one group willing to push things too far, and another group willing to paint with too broad a brush. For the short term, all that can be said is this too shall pass, in the meantime the broader community of Muslims must consider their extremists their crescent to bear (that's satire).
Yet a distinction must be observed and noted. In response to National Lampoon's regular blast of offense the American religious right threatened lawsuits (regularly), condemned NL as filth (constantly) and even (it was rumored) plotted to buy up NL in order to close it (to NL's laughing delight). Machine guns as a response to offense never even vaguely came into the picture. The difference is that the opponents (NL versus the American Right) both fundamentally believed that the system worked, that attacking the underlying system for the sake of a single goal was not a rational value judgment.
Muslims, Jews, Christians, Catholics, gays, straights, the left, the right, raise your children well. Tell them that the candle isn't worth the game, that the system in which they will live and interact will be filled with people who will not understand them or have their values. These others will sometimes be offensive, sometimes in satire, sometimes in ignorance, sometimes because of utterly divergent and conflicting values. Teach them to question the values of others and the values of themselves. Educate them to understand their own values well enough to live those values and to express those values without recourse to the machine gun. Teach them, now and forever, for all of their lives, that if we have the courage nous sommes Charlie.

Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
The Sony Hack, Strategic Questions and Options
December 26, 2014
“Shall we play a game?” “Love to. Let's play Global Thermonuclear War!” -- War Games, 1983
The December, 2014 attack on Sony by person or persons unknown has been attributed to North Korea, Anonymous, and a cast of thousands. At this point nobody really knows who is responsible. Some theories suggest that the attackers mimicked North Korean data origins and linguistic style to give the appearance of a North Korean attack. Anonymous would hardly be likely to attack resources that they themselves value, except that they have done so before and even the most brief perusal of their statements to the world show a boggling lack of understanding of cause and effect and lack of a cohesive strategy or goals. I suggest that it doesn't matter at all who is behind the attack on Sony and a cheap comedy, which, had it not achieved publicity through the Sony hack would have been entirely forgotten in three months' time.
Today, we'll play a game. We'll look at one, and only one, attack strategy which, should a nation-state such as North Korea be inclined to attack the United States, would be ever so much more effective. I stress one because it is crucial to appreciate the quantity of interrelated systems which support American infrastructure, and the need to secure them. I quoted the movie War Games at the start, and I refer viewers to the scene near the end in which the WOPR computer runs through its attack scenarios as a simulation. To a movie-goer it's time to finish off the Milk Duds and fish for the car keys. To a computer person it's all too plausible and scary as hell.
Let the games begin, and may the odds be, well, you know...
Problem Setup (Inventory):
A major big box retailer uses Just in Time (JIT) inventory to streamline costs. A large retailer has two inventory model options. They can warehouse their inventory as received or they can employ a JIT model.
Warehousing has positives and negatives. On the plus side, the retailer can stockpile an inventory of goods which means they can say definitively how much they have of which products. Because inventory is physical, the retailer can say how long they expect their inventory to last, and an interruption of the supply chain does not mean an immediate interruption of inventory. On the negative side, physical inventory means additional logistics to arrange, and that means increased cost. The retailer has to ship goods to a storage facility, offload into a warehouse, pay for the expanded storage facility and employees to operate it, sort for delivery based on inventory needs, and load a second time to ship to a retail location.
A JIT model does not entirely eliminate the costs involved with a warehouse inventory model, but it reduces those costs significantly. In the JIT model, with a sufficiently well developed computer system, the retailer holds much less physical inventory in stock. The computer notifies the retailer about inventory as it begins to run low in various locations and replacement orders are placed 'just in time' to replace depleted stocks in the retail locations.
So, if in the Cleveland retail location it requires forty-seven days to restock diapers, twenty-nine days to resupply aspirin, and fifty-three days to restock athletic socks, the computer tracks and advises on low supplies, orders are placed, orders are received and shipped and in the retail stores just in time (before current supplies are exhausted). This requires an amazingly complex information system which must track inventory, anticipated consumption, anticipated order time, delivery time from the manufacturers, and delivery time to the retail location. A sound system would pad these delivery windows and provide some extra time for unforeseen circumstances such as excess demand, weather delays, holidays, employee sick days, etc.
However, and here's the catch, in order for a JIT model to save the retailer significant costs, it is necessary to maintain a minimum of physical inventory. Stockpile too much and the retailer is back at a warehouse model and its attendant logistical requirements and costs, stockpile too little and the retailer does not have goods to provide to its customers.
Attack Setup (Infrastructure Dependence):
For our hypothetical retailer to follow through on their JIT inventory model, it is assumed that certain systems will function more or less according to expectations (again, the retailer builds some tolerance into their model). The retailer expects that the manufacturers will produce goods according to any contracts, that the goods will be shipped, timely shipment offload at the dock and forwarding to a sorting location, that the shipment will be sorted into individual quantities for specific retail locations, and that the individual shipments will be delivered to the retail locations, and that all of this will happen within the schedule specified by the JIT inventory system.
For all of these activities to take place as scheduled, underlying infrastructure must function as anticipated. Starting at the point at which the shipment is received in the United States, the receiving shipping port (let's pick the Port of Los Angeles, a major offloading point for shipments originating from Asia) must be operational. To 'be operational' the port must have electricity, fuel for delivery trucks, open and accessible roads for delivery vehicles, available labor, water and sewer service, food service, safety, support of fire and police services, warehouse security, local port-side logistics including human resources, order tracking, and communications access to manage logistics of shipments once received by delivery drivers. These are the minimum requirements.
Attack Setup: (Infrastructure Weaknesses):
California gets its electricity where it can. Without belaboring the physics, it is always cheaper and easier to provide and to consume electricity as generated rather than to store it. So the electricity supply which powers the Port of Los Angeles comes from a variety of sources, any of which may have excess capacity as required and available.
These remote electricity suppliers want the linemen and maintenance workers to be able to access the system quickly in order to move capacity from one part of the system to another as needed so that their customers have an uninterrupted supply of cold beer and the Simpsons (with any excess to be provided to the Port of Los Angeles). But the focus has customarily been on access and not on security. Spending money on security is always an exercise in proving a negative: that is, if a security breach does not happen, how can the company be sure that additional security prevented it, and that its money was therefore well spent?
So security upgrades are not always so attractive to management, employees are resistant to extra security procedures, stockholders and unions must be answered to, and installation and maintenance of security is an added logistical burden which interferes with the primary function of the utility supplier. So security upgrades do not always happen. Utilities from electricity to water and sewer and communications, including mobile communications, sometimes use hardware and software which has long been demonstrated to have security bugs, do not have redundancy built in, and in some cases, have been discovered to be using factory default passwords (readily available by downloading the manual(s) online).
Attack Strategy:
An attacker who proposes to take out significant infrastructure expects opposition. If an attacker would attack the US through its supply chain, the attacker would expect that the big box retailer including their primary logistical systems would have some protection. Similarly, an operation the size the Port of LA would have, or be expected to have, significant security awareness. So, in the classic hacker strategy, the attacker does not attack the main target(s) head-on, instead the hacker goes after the comparably weaker yet crucial infrastructure underpinnings. This is not a new or astounding approach: it is how attackers have approached complex system attacks since the beginning of hacking and the personal computer.
Attack Scenario:
In our list of minimum requirements for running a shipping port, taking out utilities for that port takes out electricity, fuel delivery, communications, ability to offload goods and the knowledge of where to put those goods or to send them. Loss of traffic controls make roads impassible even presuming it was possible to load trucks or that the trucks had fuel to operate. Employees cannot get to their jobs, and cannot do them properly even when they can get to them. Police and fire services are overwhelmed, so physical security is a problem.
The attacker has not attacked the target directly, but has attacked the systems on which the target relies to operate. Since our retailer relies on a JIT inventory model, supplies are already running low in retail stores (although it's not apparent to consumers yet). The rolling effect will be felt by nationwide shortages in under a month. Also, since the attacker is not attacking in the present tense, but rather has attacked in the past tense, there is not an enemy to target in the sense that destroying an attacker will stop the effect. The effect is inevitable once the attack is complete; it is a rolling effect which naturally follows from a collapse of infrastructure.
Post-mortem:
There are lessons we can learn from the above simulation.
First, unfortunately, humans tend not to learn by simulation. Therefore, the above will probably happen sooner or later. As a society Americans have built a complex and extraordinarily fragile structure on which they are dependent for their lifestyle as they know it. They do not secure it properly, as individual corporate entities within that structure cannot justify the additional cost or inconvenience of security. The rolling effects, once begun, are inevitable and the point of prevention (POP) has been missed.
People in silicon houses shouldn't throw stones. The systems which underpin the commercial and lifestyle model are many, varied, often unregulated, in some cases antiquated, and unappreciated in terms of the scope of their role in the overall system. To damage or destroy one element is to cripple the entire system at minimum to the degree that the system depends on that element. For America to lose its infrastructure is to lose a lot more than anticipated.
Decision makers act on the basis of motivation. If present imperatives, be they social or commercial do not sufficiently motivate decision makers to secure their systems, other motivational tools, be they financial or legislative, regulations or minimum standards linked to awarding contracts may be considered.
And, oh, yes, with all of this hanging over their heads, Americans are worried about a movie.
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
December 14, 2014
There is an underlying assumption to most technology models that all strategies will be possible. If a given technology exists, it exists in all places and for all users and can therefore be deployed. So in the face of ubiquitous technological opportunity, all technology is available for planning and implementation, and minimum standards of efficiency and even regulation are possible. However, a plan which requires that this universality of technology be an inevitable element fails the first time that this standard is proven to not be attainable.
A couple of examples should suffice. One user once subscribed to Amazon Web Service. For about 18 hours all together. They went through a fantastic smorgasbord of cloud options Amazon offered, signing up for selected features and envisioning a welding together into an amazing powerful new model of computing power and off site backup. Then reality kicked in. The internet bandwidth regionally, while technically high speed, was not sufficient to support continued robust connectivity required for AWS, nor was such a quality of service available (although it was certainly advertised). Scratch one technology model, compliments of the real world.
The same is or may be true of other technology models. Cell carriers with spotty coverage should not ethically (although they may in reality) offer a device or a service or aspects of service which assume constant or nearly constant connectivity. Chromebook performance was probably most impressive when tested in southern California, where you don't really need sunlight to get a tan, the wifi and cellular signal strength alone has to be enough to cook anyone medium rare. But it may not be the best place to test a technology which relies unequivocally on the availability and abundance of technology equal to that of test conditions for the model to be and remain successful.
This is especially true of mobile devices. By definition mobile devices are expected to move from place to place. Pick a U.S. mobile carrier at random, go to their website and browse their coverage map. Really zoom in and pan around. Think about how many contiguous miles are covered by areas of spotty coverage. Anyone doing business in the area or traversing the area on a regular basis cannot partake of the theoretical technology models no matter how advanced, or how impressive the advertising, for those models.
For a while I traveled through the area between Rockford, Illinois and Dixon, Illinois on a fairly regular basis. Based on where roads were physically located, regionally available carriers and signal strength, it is essentially a cell phone dead zone. Between one city and the other there was no cellular signal at all.
Like traveling through the desert, make sure that your car is in good shape and the spare tire has air because there is no help or way of calling for it for the next 50 by 40 mile block. Therefore GPS would work only if you had a map program which preloaded its map data. If reliant on the cell network for data, that feature also does not work. Nor does 911, AAA or calling your boss if you are running late. The model fails.
Soon this will be true of cars as well. One aspect of the Internet of Things (IoT) that technology writers love so much to tout is the connected car. Remember the Google self driving cars? They look very cool on the websites, all of the technicians standing around them in matching polo shirts and clipboards kind of brings a tear to the eye as a dream is realized and civilization takes that next leap forward. In practice the smart car probably won't be so smart after all whenever it drives out of coverage range. Will these smart cars, now dumb cars, be sold where there is not the infrastructure to service them? Absolutely. Should they be in a properly ethical environment? Probably not, at least not without a lot of disclosure.
In fact what will happen is this. Smart cars will be sold where there is not a chance in the world that infrastructure exists to let these cars be smart and companies doing the selling will hide behind what may be called the helpless peon syndrome, to wit, the companies which cannot service their products will staff the front lines of customer service with people neither empowered nor possessing sufficient technical knowledge to address customer complaints. (Nor in fact is technological education actually relevant in a scenario in which the infrastructure simply doesn't exist to provide the promised service.)
There was a televised news segment from the American South not too long ago. People who had businesses in the small town in question had what could charitably be called spotty internet service. The individual merchants had come up with a variety of workarounds even as they were all but crying with frustration that the only high speed provider was completely indifferent to the quality of service issues they experienced. And the frustration was deserved: customers were turning away, and actual measurable business was lost.
So the merchants had a calling network whereby they would call one another if they discovered that the internet was back up first; they had pre-printed signs they periodically hung in their windows that they could not process card payments for the time; they had the wiring strung up beside the cash register so they could lean over and disconnect their business phone(!) and plug in the card payment line. Into this brave new world the internet provider did not dash to fix the problem. Instead customers got empathy statements from unempowered peons in a deficient coverage model.
All of this is just to observe that sometimes, more often than may be thought, technology models are encumbered by lack of infrastructure, human nature, greed, indifference. These qualities don't appear anywhere on a Gantt chart when a system model is envisioned, but perhaps they need to have a place and value even as an intangible. Call it the anti-goodwill.
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
Banging the Rocks Together: A Life Skill for when the Internet fails
November 14, 2014
“Broadcasting around the galaxy, around the clock...we'll be saying a big hello to all intelligent life forms everywhere...and to everyone else out there, the secret is to bang the rocks together, guys.” -- Hitchhiker's Guide to the Galaxy
The Israeli Homeland Security website addresses the security (or lack thereof) of the Internet of Things in an article dated November 12, 2014.[1] The thinking in this article correctly notes that all of the many current and future components of modern life which send information to and receive information from the Internet are vulnerable to attack. IHLS also observes (correctly) a paradox: Systems must be simple enough to secure, but require complexity for the current future application in the Internet of Things.
The problem is that this very paradox needs to be addressed realistically. IHLS insists that components critical to infrastructure be “completely clean, uncontaminated” but flexible enough to meet current future demands. This sounds rather like a middle manager banging his fist on his desk and yelling to just do something without understanding the system realities. It sounds like Dilbert. It probably looks great on a planning report, though. Let the legislators talk about a system which is secure and uncontaminated and flexible. They don't know what a realistic design parameter is anyway.
The IHLS theoretical system has the specifications that it is
- flexible and upgrade capable (that is, modular)
- minimalist (that is, simple enough to keep clean and protected)
- and let's add singular (that is, there is only one clean uncontaminated attack vector to defend)
What you have effectively designed is a system, the successful attack of which, will bring down an entire swath of infrastructure. Further, by limiting the attack vectors in such a system, you have virtually guaranteed that the limited vectors will be researched exhaustively by attackers. In information security (infosec) there is a truism that defense is always playing behind offense. In other words attackers always have the initiative, defense is always reactive. Putting all of your eggs in one basket, all of your faith in one component of a system, and a system with unrealistic requirements in the first place, virtually guarantees an eventual successful attack on infrastructure.
The better answer is dynamic redundancy with multiple and varied components to protect each critical infrastructure system and an infosec team to maintain it against the inevitable attacks. Then when the inevitable attacks impact one part of the system, there are redundancies to maintain infrastructure while the effects of the attack are repaired. Redundancy should not be confused with minimalist design parameters. Minimalism, that is, minimal system components are more desirable than complexity when the same or similar benefit results, and that should not be seen to conflict with the concept of redundancy. Unfortunately such a system will probably not happen for a couple of reasons.
First, non-technical (including legislators) people do not really want to hear that threats to a system are ongoing, and will continue into the indefinite future. They want to hear that a problem is resolved, not that it can never be; by contrast the IHLS proposal sounds more sexy.
Second, the cost of redundancy is not as easy to explain when the redundancies are guaranteeing a system rather than actually being responsible for its real time operation. Non-technical people (including legislators) only truly appreciate that a redundancy is necessary when it's not there.
Non-technical people (including legislators) do not want to hear about the details. They want the present and future benefits of systems, to lay out their requirements to systems designers while not understanding that their requirements are unrealistic, in some cases bordering on fantasy. Non-technical leadership may not want to hear the details, but the devil is in the details.
So I was outside for awhile today banging some rocks together in practice for the apocalypse this sort of thinking inevitably portends for a society reliant on Internet based infrastructure. It seemed more useful than banging a fist on a desk and shouting for an unrealistic infosec model.
[1] Lachman, Dov. Protecting Internet of Things from malicious attacks. Israel's Homeland Security Home. November 12, 2014. http://i-hls.com/2014/11/protecting-iot-malicious-attacks/
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
Why a Browser Blacklist?
November 11, 2014
I have a browser extension for Firefox and its full service big brother Seamonkey which permits me to block certain URLs or domains. Some reasons that people use browser blacklists are to block
a) pornography or other “objectionable materials”,
b) phishing or other sites with bad security reputations, or
c) sites which interfere with productivity, such as kitten videos or online games.
These are fine reasons to block sites, and I understand them. However, I did not begin using a browser blacklist for any of the above reasons.
I began using a blacklist because of the advertising and statistics servers which all too often hang my browser. Web sites track their popularity, determine advertising rates and use geolocation services to serve 'locally relevant advertising'. Yet, at the same time, a news site's specialty is news, and entertainment sites hope to entertain. Neither are experts at serving 'relevant advertising' or generating the statistics they crave. As a result they often use outside services to collect this data and serve advertising for them. It can be annoying, and I won't say that I like it, but I do understand the concept of advertising based revenue.
However, a line is crossed when these sites a) use advertising or statistics services which are so slow to respond that the browser hangs for a notable period of time, and b) so poorly craft their sites that the page hangs until the remote advertising or statistics server responds, however long that may be. Further, these third party advertising and statistics services do not just serve a single site, they provide multiple sites with their services. In theory they should have enough server capacity and bandwidth to provide this function in real time to all of their client sites, so that all client sites load seamlessly, in practice that does not always appear to be so.
In response, I use the following model to determine whether an advertising or statistics or 'other' domain makes it into my blacklist.
- I do not blacklist such a service simply 'because I can' block advertisers or data miners. Life is too short for that.
- I blacklist such a service when it slows down a web site enough to get my attention, AND
- the 'hang time' is long enough for me to become annoyed, bring up an electronic sticky note, note the domain (see graphic)
If these last two elements are true, I feel no more guilt about dropping them into my blacklist than a site owner, advertiser or data miner feels about hanging my browser.
I am currently testing Silent Block 1.2.3 for Seamonkey and Firefox, and it seems to make a notable difference in browser speed. I have not used it sufficiently long to make a meaningful overall assessment of the extension, but it does seem comprehensive and flexible.
As of this writing, domains which have slowed or hung my browser long enough for me to comfortably note them without hurrying and are therefore (in my opinion) worthy of a place in my blacklist are:
b.scorecardresearch.com
scorecardresearch.com
log-b.liverail.com
liverail.com
googleanalytics.com
googlesyndication.com
ace.advertising.com
doubleverify.com
ping.chartbeat.net
chartbeat.net
doubleclick.net
log.outbrain.com
outbrain.com
ml314.com
loadm.exelator.com
exelator.com
browser-update.org
p.acxiom-online.com
acxiom-online.com
Your mileage may vary. Also worth noting is that some third party domains serve actual content, albeit with agonizing slowness, and may in fact provide elements of a client site which you may want to see. Thus a site may load with errors, load incompletely, or appear to be incorrectly formatted if you block third party domains which provide that content. A manual blacklist may be a useful tool, but which domains to add to it is a matter of trial and error. A Google search for a domain is often enough to indicate if it's a data miner, advertiser or actual content provider. In the end, a third party domain has to really slow me down (in my opinion, so this is entirely subjective) and probably more than one time, before I bother to blacklist it.
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
On the Butlerian Jihad
November 9, 2014
“Once men turned their thinking over to machines in the hope that this would set them free. But that only permitted other men with machines to enslave them.” -Dune, 1965
This an interesting perspective on a couple of counts. Dune was a novel from 1965; computers as we know them today did not exist. Despite the lack of modern computers, it was assumed that man would abuse their thinking machines to the detriment of other men. Although Dune does not provide a lot of detail on what was called the Butlerian Jihad in the novel, it is presumed that some sort of social backlash against this abusive control by computers was anticipated by the author.
The year 1965 was before the personal computer, before Bill Gates said that 640K ought to be enough for anyone, before the rise and fall of the Blackberry, before Google stated that anyone with anything that they wished to keep private ought not to be doing that thing. It was before the birth, short life and quiet death of the concept of opt-out, both on a commercial and governmental level. 2001: A Space Odyssey was still a couple of years away, and IBM's Watson, while quick at data regurgitation, but strangely limited where relationships on multiple levels were concerned, was still 50 years in the future. Despite its time, Dune was prescient about where computers would eventually go, as directed by the worst nature of their human operators.
One concept which Dune suggests is that computers will be used to abuse others. Multiple examples are apparent in the information systems of today. Governments now analyze all data generated by their own citizens just on general principles. Spyware and viruses steal information from computers through stealth. Corporations collude to create a social atmosphere for information systems in which all user privacy is compromised and all user data is made available for use or abuse by any group for any purpose regardless of vendor.
Another concept that is suggested even in the limited writing in Dune is that a backlash against the overreach and control by computer systems will come to be necessary. This suggests a concept which has proven true throughout history: that given the option to continually develop an abusive system or practice to one's own benefit, even to the detriment of others, such development will continue to a crisis point. It is ultimately a social or political restriction rather than a logical or technological constraint which eventually limits or adjusts the concept being developed.
There are secondary, but no less valid elements of such a paradigm. This is precisely the sort of relationship a Watson would miss and may not be completely understood by either data vendors or users. When a model becomes mandatory or quasi-mandatory it is an indicator of several things. First, no matter how such a paradigm is portrayed, if it is imposed unilaterally by a vendor or government, it is probably not desired by those on whom it is imposed. Second, if the paradigm is applied equally or mostly equally among all vendors, or by one's government, there is not really an opt-out option to be had. Third, the suggestion that the only way to avoid such an abusive paradigm altogether is to not use technology is disingenuous at best, cynical deception at worst. These elements, taken together, suggest that to use technology one must tacitly accept abuse.
Another interesting element, again, historically demonstrated, is that when a situation reaches a crisis point, the remedy is destructive of both the elements which caused the paradigm to become a crisis and also the underlying structure which would have survived had the paradigm not been pushed too far. A peripheral, but again no less valid element, is that although this historical reality is apparent in hindsight, in the present it is difficult (but not impossible) for the participants to say for certain when things have been pushed too far, and a crisis is imminent.
From World War II until the mid-1970s it was permissible to smoke anywhere. People could and did smoke inside hospital rooms, and Big Tobacco was one of the bluest of blue chip stocks. Times change and paradigms shift, and by the very nature of the concept the outcome will be unpredictable. Today, in certain cities you cannot smoke out of doors in many places, while cars still drive along spitting out orders of magnitude more pollutants than any smoker ever could. All of which is to say that a paradigm shift is not predictable in the details, or, as Michael Chrichton wrote, a paradigm shift is like death: you cannot see how it will work out until you are on the other side.
Certain elements are key indicators of an impending crisis, among them mandatory or quasi-mandatory participation and a strong social or political backlash should be warnings. Also, when the defense of the paradigm does not address the fundamental paradigm flaws precipitating the crisis, the impending crisis is not averted. For example, if a corporation or industry claims a right to free speech or that they have secured a user agreement with an excessive privacy policy in order to continue to violate the privacy of its users, that corporation or industry might be within current legal parameters, but at the same time has failed completely to understand or address the impending crisis. Interestingly, this is exactly the sort of missed opportunity that historians love to analyze in the wake of a crisis.
Certain behaviors and reactions are currently apparent. Corporations hide behind legal theory and lawyers rather than address the fundamental issues which cause customer dissatisfaction with their practices. This indicates awareness of the problem, disinclination to address same and suggests that further development of the same model will continue in a similar direction. Likewise, governments hide behind national security arguments, and like corporations, ignore the underlying concerns while the model develops further.
Ignoring the real underlying concerns of users, a willingness to test the limitations of current models, assumption that the status quo of generalized abuse will evolve and continue indefinitely, and ignorance of history, whether intentional or otherwise will precipitate a crisis in the information age. If history is any example, the pattern will continue, and be pushed beyond the brink until the crisis unfolds. After that crisis, there will be no going back to even a portion of the model which is rejected. Similarly, if history is any example, it will be impossible to make most people in any given present believe this until a crisis is inevitable.
Update:
November 14, 2014
I wrote on the Butlerian Jihad a day before U.S. Senator Ted Cruz tweeted on Net Neutrality in what can only be most charitably read as amazingly uninformed about what Net Neutrality actually is. The best response to Senator Cruz and summary explanation of Net Neutrality I have seen comes courtesy of The Oatmeal. See the Senator's tweet and The Oatmeal's response immortalized online (Warning: the language is PG-13 if that offends you).[1]
Net Neutrality in summary is a good thing. An Internet without it is uncomfortable to conceive. The Internet would not collapse without it, and information would still be available, it would just be more difficult to get balanced news, open source software and have reasonable media choices. For example, in the current environment, in which Net Neutrality can be said to exist, the video about Obamacare's economist calling American voters stupid still took several days to make it to center and left of center news media; open source software is normally donor funded and can't compete financially with a Microsoft, Apple or Google; Comcast already has shown with Netflix how choice of media could be restricted and prices raised arbitrarily.
Users would work around a lack of Net Neutrality, some more effectively than others, but most of them would definitely be unhappy about the new, skewed Internet. I am torn about the reality of an internet sans neutrality, and what it means for the Information Age in the long term. On the one hand, I am selfish; I want my balanced news, open source software, and media choices.
On the other hand, the current cyber environment has many problems of which Net Neutrality is but one. Even if Net Neutrality becomes the regulation of the land, there are still these other crucial concerns which the debate over Net Neutrality does not address. There are still concerns with corporate concepts of individual data privacy, national security, ever evolving cybercrime. None of these issues would be addressed by regulation in favor of Net Neutrality.
As I said above, historically humans have a tendency, in fact can be almost guaranteed, to push situations too far when things are going their way until a crisis point is reached. There is no reason the expect that an Internet without Net Neutrality should be any different. If Net Neutrality is defeated, one can expect higher prices, less choice, and countless models to build on and monetize the fact that users can be made to pay more for certain types of content or content from specific vendors. This will in turn result in a vast unhappy user base, lawsuits, uncertainty, and companies paying lip service to consumers but little else. This in turn might push the inevitable cyber crisis that much closer.
And that may be more beneficial in the long run than Net Neutrality.
[1] The Oatmeal. Dear Senator Ted Cruz, I'm going to explain to you how Net Neutrality ACTUALLY works. November 10, 2014. http://theoatmeal.com/blog/net_neutrality
Share this on ![]() witter
or
witter
or ![]() acebook.
acebook.
Google and Chrome, Linux and Chromium, Firefox and Flash Player
October 31, 2014
Many Adobe Flash based videos and games will not operate properly in the Firefox browser for Linux any longer. This is due to Adobe's decision to no longer support the Linux operating system with a direct download browser plugin for Adobe Flash player. [1] Instead, Adobe is providing a Flash plugin called Pepper and is making it available only in the Google Chrome browser.
However there is a problem with this approach, and that problem is Google. As many users have noted, Google, for some inexplicable reason decided to not support CentOS/Red Hat/Scientific Linux with their recent version of the Chrome browser. In itself this is not a problem since Linux offers the Chromium browser for the Chrome fans out there, and no doubt the Linux community will eventually develop a Flash plugin of their own for all browsers. However, for the time being, the problems a Linux user must resolve to have a browser with updated Flash capability are these:
- Adobe does not offer a recently updated Flash player browser plugin for Linux, except as packaged in Google Chrome,
- Google has snubbed or ignored several of the major Linux distributions in the latest version of Chrome,
- Google does not currently offer previous versions of Chrome for download.
Here are some simple steps to get the Pepper Flash plugin from Chrome installed to Chromium. (I installed Chromium and the Pepper Flash plugin in CentOS 6 32-bit edition.)
First download and install the Chromium browser. If it is not available in your distribution natively, you can get it at http://people.centos.org/hughesjr/chromium/6/
Next download and save (do NOT install) the latest Google Chrome RPM installer available at http://www.google.com/chrome/
Now open the Google Chrome installer RPM with an archive manager. In other words, do not run the installer with Yum or Package Manager, instead open the RPM to browse its contents.
Next extract the folder /./opt/google/chrome/PepperFlash/ from the Google Chrome installer. It is generally a good idea to keep the folder name for clarity. So, you may save the extracted folder and contents as ~/PepperFlash/ or similar. If things went properly, you now have a folder called ~/PepperFlash/ or similar containing a file called libpepflashplayer.so. You can now close the Google Chrome installer RPM and delete it.
When you installed Chromium, Linux created a launcher shortcut. That shortcut launches Chromium with the command
/usr/bin/chromium-browser %U
Using our example, change that shortcut to read
/usr/bin/chromium-browser --ppapi-flash-path=~/PepperFlash/libpepflashplayer.so %U
Restart Chromium, and your Flash based content including games and videos should now be available.
That's it, you're done.
[1] http://www.adobe.com/devnet/flashplatform/whitepapers/roadmap.html
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
The New GIGO
September 29, 2014
Information systems originated the concept of garbage in, garbage out with that concept meaning that at the design phase of a computer system proper attention to the accuracy of information as well as the programming logic were necessary. This was not as obvious as it would seem on the surface, but nonetheless unavoidable. The cleanliness of programming logic was not in itself useful if the assumptions made about the data were inaccurate; similarly if the processing of fundamentally accurate data was incorrectly weighted by the programming code, the quality of the resulting information was suspect. Therefore neither the input data nor processing assumptions could be incorrect, and to the degree that they were (garbage in) the results were assumed to be flawed (garbage out).
But the concept of GIGO is in itself limited, and perhaps limited in a crucial area. GIGO makes the assumption that there is an interface singularity; an input phase; a stage at which an information system is tested as accurate with regard to data and processing assumptions, after which, garbage in having been protected against, garbage out will not occur. Information systems project managers know, on the other hand, that it is necessary to update a system more or less constantly, and in fact as soon as one cycle of systems development ends the efficient long term project essentially begins again. However, this is a long term development cycle. It fundamentally conflicts with a culture of the 140 character tweet, the 160 character text message, and the concept of immediate gratification.
This distinction is especially telling when one is attempting to understand and predict human behavior. Human behavior is in fact more like weather prediction than a straightforward, complete analysis. At one time it was assumed that given sufficient computing power to assess the variables, long range accurate weather prediction was possible. In fact, the variables were so many and incompletely understood, both in scope and impact, that weather prediction on the scale anticipated, ultimately failed.
It may be theorized that as human intelligence deteriorates in the face of a culture where a complete communication is contained in 140 or 160 characters, it logically follows that prediction of human thought will become more possible and precise. In fact, with fewer variables (less intelligence on the part of the subject, or ability to focus on minutiae) prediction will likely become more probable. However, the standard of probable makes predicting human behavior ultimately no more accurate than long range weather prediction.
In addition, like weather prediction, once one improperly quantified variable deviates from the prediction, all data based on that variable becomes inaccurate to some degree, further analysis yields not only increasingly inaccurate results, but also further inaccurate input, and the model inevitably skews to the point that the computer model bears no real resemblance to actual results. In other words as garbage in become an inevitability, so does garbage out become equally inevitable.
Having said as much, it must also be noted that complete, accurate predictability of either weather or human behavior may be seen as a philosophical aspiration but that that unattainable aspiration does not render the quasi-accurate prediction meaningless. Even though weather prediction cannot be made accurately into the indefinite future, and many predictions are grossly wrong, a weather forecast is still a generally useful tool, in context, and will full regard to its limitations. Possibly, and in fact probably, MIS or CRM systems which attempt to divine human behavior, motivations and reactions are doomed to hit the same point of inevitable deviation. Such models may be assumed to have the same conceptual degree of accuracy or inaccuracy, value and limits as a weather forecast. Similarly, such models may be seen to be generally useful, but neither all knowing nor completely reliable, and in fact subject to the occasional gross inaccuracy, and requiring constant reassessment.
Therefore, as with weather prediction, listen to the forecast, but like the old timer whose knee twinges when it's going to rain, the twinge may be no less useful a predictor. Thus management instinct may challenge the the best packaged MIS or CRM systems in terms of predictive ability.
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
To Kill a Mockingbird, Once and Only Once
September 19, 2014
Question: How is a rock and roll song like a great novel?
Answer: When it's a one hit wonder, it's still a hit.
Harper Lee, Bram Stoker, Mary Shelley, Margaret Mitchell. One hit wonders, all. That one time, that one magical time, they got all of the way under the ball and hit it out onto Ashland Avenue. But, when you manage, through brilliance, skill, luck, the beneficence of God or the universe or the Great Spirit, or what you will, to get not a piece of it, or a slice of it, but to get all of the way under the ball that one glorious time and to smack it completely out of the park, what you do not do, what you must not do, is to run out onto Ashland Avenue and try to hit the ball a little further. It's out of the park. It's gone. Na, na, hey, hey, kiss it goodbye.
Harper Lee rarely spoke of Mockingbird. True, she wrote to editors regarding the proposed censorship of Mockingbird by small minded school districts of her time. But her commentary on Mockingbird itself was limited, mainly consisting of the observation that the story was now told, that there was no more of that story to tell, and that any further attempt along that line would be an inferior rehash. In other words, na, na, hey, hey, kiss it goodbye.
It is surprisingly difficult for me to write on this topic, although I feel so strongly about it, simply because I understand the concept so intuitively and completely. It is, to me, so obvious a point as to be pointless to belabor it. It should not need to be said. To Kill a Mockingbird, Dracula, Frankenstein, Gone with the Wind. Their stories were told. They were not told well, they were told surpassing well, they were told superbly. So, na, na, hey, hey, kiss it goodbye.
In an age of sequels, prequels, and we-cannot-think-up-new-ideas-so-how-about-a-rehash-quels, in an age where we do remakes of existing stories rather than demand creative and original content, in an age in which some movie studio genius decides that three or five sequel movies maximizes ROI (and is right in that assessment!), I cannot help but appreciate someone who knows how simply to STOP telling a story when it is finished. To borrow from Pat Conroy, these stories have entered the bright and dazzling city of memory.
In that bright and dazzling city of memory, they will dwell, and there I will visit them occasionally. When I visit them there, they will bring me joy all over again. But their stories are told. Their stories are complete. If those stories expand over time, it is not the stories which have changed, it is I who have changed, and can more fully appreciate their tale.
So to Harper Lee, Bram Stoker, Mary Shelley, Margaret Mitchell, and all of the other one hit wonders who told a tale which changed me, thank you. If that one time was all that you had in you, what does that matter? That one time was enough. Na, na, hey, hey, kiss it goodbye.
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
May 12, 2014
Reading a news item on California's proposed mandatory kill switch for stolen mobile phones, one link led to another and I ended up at the The Wireless Association website, more commonly known as CTIA. Now, CTIA's site has a lot of good advice on securing your phone. I'm a big fan of password protecting phones, backing up the data, encryption and the like. Those are all good practices, and people should apply them.
CTIA describes itself as “an international nonprofit membership organization that has represented the wireless communications industry since 1984. Membership in the association includes wireless carriers and their suppliers, as well as providers and manufacturers of wireless data services and products.” [1] In other words, this is a group which represents the mobile industry, which is in no way the same thing as representing consumers.
CTIA is generally opposed to a universal, irreversible kill switch for mobile devices. Their argument goes that a hacker could disable multiple phones with specially crafted SMS or other attacks, leading to the mobile equivalent of a DDoS attack. In the case of this single scenario, this one approach to mobile phone theft, they are correct. Such a kill switch could and most certainly would be abused. I would also add to hackers, abusive spouses, stalkers and other miscellaneous debased persons who would no doubt abuse such technology on an individualized basis.
In response to such a kill switch, CTIA suggests a kill switch app which would be reversible, so would give a reversible ability to the consumer to prevent their phone from being used on a mobile network. This sounds like a decent compromise on the surface, but it has some problems if it's the only mechanism offered to address the problem. First, it applies to mobile devices. By definition, these devices are moving from place to place with their owners. Yet consumers who would implement their kill switch app in the event of a theft or loss of a device, must have the internet available to invoke it, problematic since their immediate connection to the internet has just been lost or stolen (and in some cases, consumers cannot afford to maintain a second way to get online at all). Additionally, a kill switch app which is reversible suffers the same danger of becoming a tool of hacking and harassment as the irreversible version. Rogue SMS, abusive spouses, stalkers and the like could still use it effectively.
Where I differ from the CTIA's perspective is in the available options. CTIA seems to suggest that there are three major options: consumers using best practices (a great idea) or a universal, irreversible kill switch (which is problematic), or a kill switch app (equally problematic). From the perspective of a group which represents the mobile industry, this may be reasonable. After all, what these practices all have in common is this one simple element: They require almost no cooperation on the part of mobile providers. The effective limit of mobile providers' responsibility is essentially to request that mobile device manufacturers include a specific app in the pre-installed software they load onto their devices. That's about it.
A reality which the CTIA's limited viewpoint ignores is this: Mobile providers have been able to track the multiple serial numbers of a phone which accesses its services for years, for the most part.
Suppose that you were to call your mobile carrier and report your phone stolen, and even to contest the cost of international calls made on that phone during the period when you thought your phone was lost and not actually being used by a thief. The mobile provider will tell you that you are responsible for all charges until the time that you reported the phone stolen, and that they, the mobile provider, can prove the validity of the charges specifically because, if push comes to shove, they can document that a specific handset or handset-and-SIM-card combination made the calls and incurred the disputed charges.
The mobile provider can document these charges because they track the various serial numbers of mobile equipment making calls on their network. So the mobile provider can and will tell you that your handset, identified by serial number (called an IMEI or MEID depending on the technology), and/or your SIM card (again, technology dependent, not all U. S. mobiles use SIM cards) made the contested calls. In most cases that information exists on the providers' records.
An industry database to block reported stolen devices would not be a perfect system. Stolen phones are sometimes resold in other countries. There are even knock off copies of major brand phones from cheap manufacturers which do not have an industry standard serial number programmed into them. So there are cases in which a stolen phone may be used and slip through the cracks in an imperfect system created and maintained by mobile providers. Nobody is claiming perfection for such a system, but any such gaps would be both limited and understandable.
I say that information exists in the providers' records in 'most cases' because by their nature mobile phones move about, roam on a partner's network, and even travel out of the country. There are different levels of age, infrastructure, investment and compatibility of systems among these various networks, and some records will not have all device information documented completely or compatibly.
Therefore an industry database of lost and stolen devices would not be a perfect system. However, if the average thief or opportunist knows that a lost or stolen phone cannot be reactivated short of a lot of luck, technological expertise or the ability to resell a stolen device overseas, incidence of mobile theft would plummet.
A reversible kill switch app designed to disable a stolen device makes the assumption that the lost or stolen device has not been wiped or reprogrammed by the thief or purchaser. Software is ultimately changeable, but a hard coded serial number is much less likely to be changed and is therefore a far more secure tool for device identification. Additionally, leaving the identification of the device in the hands of the people more able to use the minutiae of mobile technology (the providers) is more effective than expecting consumers of varying levels of technological sophistication to be able to disable a phone effectively.
Looking at the various options potentially available, while a reversible kill switch app is, or can be at the consumer's discretion, a valuable addition to a mobile phone, the one most effective common point of control is the common point which incorporates both information and minimum standards of expertise: The mobile phone providers alone have the information and access to create, maintain, and effectively use an equipment serial number database, still the most effective means to block a lost or stolen mobile device.
Now all that is really needed is for mobile providers to step up and be responsible.
[1] CTIA. About Us. Retrieved May, 12, 2014. http://www.ctia.org/about-us.
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
HOWTO: Automate temperature monitoring in CentOS Linux (a/k/a Build your own Stuxnet Day)
April 29, 2014
Part I - Argument
This last April 25th was the day that I built my own Stuxnet and burned out a power supply. Stuxnet was a virus which in effect caused the hardware (centrifuges) used in the Iranian nuclear program to run so fast or irregularly that they burned out. This was said to be directly responsible for slowing down Iran's nuclear development process. For those with an interest in infosec, this is an interesting concept with potential applications all over the real world.
Power stations have been a special point of contention as many of them are still using legacy equipment with little or no security layer, and still others use the default passwords on control systems which directly control physical equipment. Some people are astounded that this equipment is not systematically attacked, and others believe that China, North Korea or other rouge nation states are simply accumulating an ever expanding database of vulnerable equipment while waiting for the most opportune moment to take down vast amounts of enemy infrastructure at one time.
Part II - Built my own Stuxnet
As for my Stuxnet experience, the other day I was fiddling with the computer and I went into my BOINC settings. I had noted that the BOINC client I run in Linux was only running at 50% efficiency and decided to see what it was capable of. In fairness to the people at Berkeley, they do warn on their settings page that CPU allocation percentage can be reduced to reduce CPU heat. So I noted this, and adjusted the CPU percentage up, but I watched it.
I was thrilled to see that I reached > 2 GFlops, but after considering the potential for overheating, I lowered the percentage again half a day later. Too late. When I next used a physical component (several hours after lowering the CPU speed to previous levels, I opened the CD drive), I burned out the power supply. Bang! Down went the system. One new power supply later, I am back online (and running BOINC at 50% efficiency).
A couple of interesting points occur from this lesson:
- Even though I decided to see what my system was capable of, I also believed that I had built a more robust system than normal (since I have some extra goodies in my Linux box, I also have three extra cooling fans in a gaming configuration),
- I could run the air conditioner 24/7 to offset the extra heat, but that is not practical and the electric bill would go through the roof; capability does not equal practice,
- I was using a civilian system (BOINC). Not something (too) specialized or exotic, and not something that one would think would or could likely render a computer inoperable,
- A civilian system, if hacked, could be used to burn out hundreds or thousands of computers simply by tweaking this setting because not all systems have sensors or software capable of monitoring temperature spikes (along with my new power supply, my Linux box now has temperature sensors and software up and running),
- Even a system which can monitor itself needs to be further specialized to take specific action in the event of certain conditions. Anything less requires human interaction and monitoring,
- This box was offline for the time it took to get a new power supply ordered, shipped and installed. I have other ways of getting online and backups of key files. One hopes that companies which have critical systems have the wherewithal (vendor lists, technicians on call, individuals authorized to go to vendors and purchase parts, leadership hierarchies, transportation plans, failover systems, in other words, common components of risk management) in place for rapid system recovery. From previous experience, I somehow doubt that these plans go far enough or consider all scenarios.
So, in the aftermath of BYOSD, I decided that I wanted my Linux box to have temperature monitoring active and to act without human intervention in the event that system temperature went too high. Which led to:
Part III - HOWTO: Automate temperature monitoring in CentOS Linux
- I started with a a box running CentOS Linux 6, Gnome 2 and Python 2.6 with tkinter installed,
- Install lm_sensors. lm_sensors is the generic sensor monitoring service, a separate GUI to monitor lm_sensor data is required,
- Run sensors-detect.sh as superuser. You can find it at http://www.lm-sensors.org. This script will offer to detect the correct temperature probe(s) in your mobo (that's Geekish for the English word motherboard) and write the correct .conf file,
- Optionally install gkrellm, which has a kind of decent interface for many things including lm_sensors, but runs as an opened application, not a taskbar icon. It's not what I wanted, but it's cute enough to mention,
- Install gnome-applet-sensors. This may not be found in your CentOS packages. If not, search online for gnome-applet-sensors-2.2.7-1.el6.rf.x86_64.rpm or equivalent for your system. With gnome-applet-sensors you will be able to add a monitor to your taskbar for the temperature probe(s) in your mobo.
You should see something like the following on your taskbar now.
Well and good, you can now monitor temperature on your taskbar, and that may be enough for many users. But, if you want Linux to monitor things for you, and take action if things get a little too hot, let's continue:
- Edit /etc/sudoers to give sudo permission to run /sbin/shutdown -- like this (as one possible example):
root ALL=(ALL) ALL
user ALL = NOPASSWD: /sbin/shutdown
- Next, create a Python script to a) pop up a graphic notification that the box is shutting down, b) mail an email warning to the root system mailbox, c) shutdown the system. This script will need a text file for the email and a custom .GIF graphic.
The .GIF just has any message to indicate that the box is shutting down because of high temps. Mine looks like this:

The text file is in this format:
Subject: Warning! This computer was shut down due to high temperature!
The python script for this process acted as required automatically.
Please monitor temperature.
The Python script looks like this:
import sys # allows for direct OS command execution
import os
import time # necessary to make program slow down if desired
from Tkinter import *
import tkMessageBox
import tkColorChooser
import base64
import urllib
root = Tk() # The base window, a canvas.
root.title('Shutdown Imminent!')
# This inserts a graphic/logo
#
# .gif format req'd, jpg and png not valid data types
URL = "/home/user/scripts/hitemp.gif"
link = urllib.urlopen(URL)
raw_data = link.read()
link.close()
next = base64.encodestring(raw_data)
image = PhotoImage(data=next)
label = Label (image = image)
label.pack()
mailcommand = "sendmail root@localhost.localdomain < /home/user/scripts/hitemp.txt&"
os.system(mailcommand)
shutdowncommand = "sudo shutdown -h -v +1&" # causes shutdown in 1 minute, -v optional
os.system(shutdowncommand)
root.mainloop() # Done creating main window
- Now use the command python /home/user/scripts/hitemp.py as an alarm in your gnome-applet-sensors preferences:
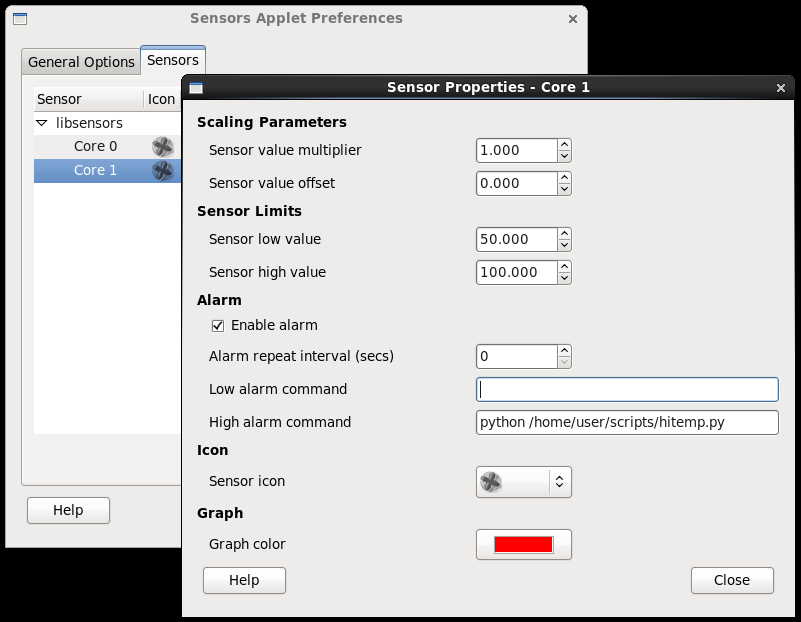
If you prefer gkrellm as a monitor, it has a similar launch-on-condition option:
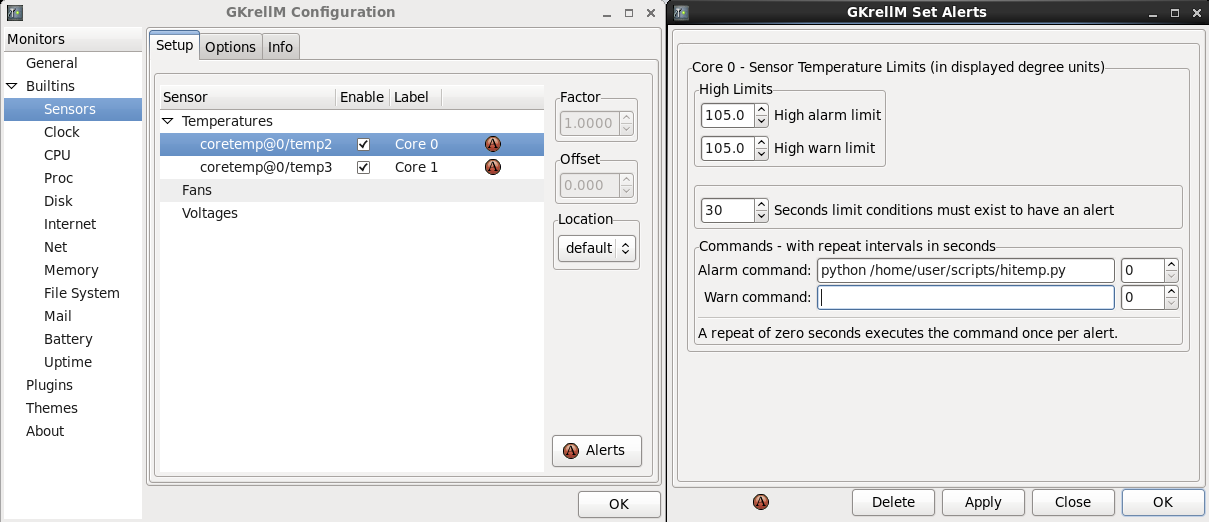
If the alarm level temperature is reached, the Python script executes: notifies the system mailbox, pops the graphic, and shuts the box down a minute later. When you turn on your Linux box later, you'll have email to the effect that it was shut down because things got too toasty inside the case, and the computer protected itself.
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
Wallpaper, Screensavers and Webcams, oh my!
March 6, 2014
Short post today, if for no other reason than that the story is not so exciting, but the result is nice. I use a screensaver which has a module which will pull random images from the web into a collage. That's it, that's largely all that that module does. I was looking at the option of limiting that module to a webcam shot of Paris, London, New York, wherever there is a public webcam which has a good view. For technical reasons, that came be impractical at this time, so I changed around the code I had written and came up with something different, but still nice, and actually closer to what I was picturing in any case.
Submitted for your approval, a program called Paper Shaper. It randomly pulls a JPG image from a user maintained list of webcams, OR from your offline wallpaper gallery, OR randomly from one or the other and saves it to a specific file and location. Since the file name and location do not change, it can be selected for wallpaper and updates automatically. Simple enough. Here are the very basic technical specs.
- Written in Python 2.6 [1]
- For Linux only
- Requires the lynx browser [1] [2]
- I am using it in Gnome 2. It should work with any GUI which lets you select a JPG for wallpaper
- Tested and worked beautifully in Gnome 2 (CentOS 6),
KDE 4 (Ubuntu 12.04), MATE (Fedora 20)
- Paper Shaper automatically updates wallpaper however
often you like, so it only needs to be run once at start
up
- Assumed path names are /usr/bin for lynx and ~/com.pkcarlisle/papershaper for Paper Shaper's files. If you would change these paths just modify the Python code in papershaper.py with the text editor of your choice
- Full documentation in the download archive
[1] These applications should be
available with most if not all Linux distros.
[2] Installing the lynx browser does NOT replace or
change or interact with your current browser such as
Firefox or Opera IN ANY WAY. You install lynx in
addition to what you have now, and neither interferes
with the other. Also you will not be using lynx
manually, Paper Shaper invokes it in the background as
required. You will not have to learn a new browser, move
cookies, bookmarks, etc., or even know that lynx is
there once installed.
This program is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version. This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
And here it
is: Download Paper Shaper from
Sourceforge.
It is purely optional, as just
stated...you may use Paper Shaper forever and a day at
no cost, but if you would like to contribute something
for Paper Shaper, it will certainly encourage me in
developing future projects and distributing them
through similar channels. To contribute, just choose
Paypal or bitcoin.
Last thing... As always, enjoy!
| Paypal
donations: |
Bitcoin
donations: 1FffXX55hAHWTS3cmHekDT4z2adfRwdKRC |
 |
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
A Tale of Two Printers (including Tricks and Counter Tricks in Windows 7)
September 19, 2013
My printer is one of those old dinosaurs which will probably still be operational at the turn of the next century. For my part, since I note that this printer was made in the days when plastic was not so thinly poured that planned obsolescence was implicitly understood, I will be hanging onto this printer just as long as I can do so. Getting it running was an interesting exercise.
The printer model is an Apple Laser Writer Select 360. Apple did not really 'make' this printer. In fact, except for an extra Apple specific port, this printer is actually an HP LaserJet III under the hood. Since I have a Linux box and a Windows 7 laptop, I did not specifically seek out an Apple printer. In fact, I took it in exchange for setting up a router for a rather attractive lady as a sort of Lady and the Tramp rolling-of-the-meatball gesture (which ended up going exactly nowhere). In fairness, I was told that the laser printer was broken, and by a near miracle I actually managed to repair it (a lot of people assume that if you know computers, you also can repair printers, monitors, phone lines, cable boxes, car stereos, etc., but as a rule I cannot repair laser printers, and don't even want to try).
Thus did I end up with an Apple printer which was sometimes not an Apple printer to run with Linux and Windows 7. Linux offers a driver for the Apple Laser Writer Select, and it set up quickly and easily. As usual, the joker in this deck was Windows 7. Windows XP included a Laser Writer Select driver, but Microsoft, in its never ending collusion to get people to buy new hardware, did not include a Laser Writer Select driver in Windows 7, nor did they include an HP LaserJet III driver by default. However, there is an extended Microsoft printer driver database which does include the Laserjet III. Here's how to access that extended driver database.
This was done in Windows 7 Professional Edition. The process includes the sort of insane backwards thinking that only Microsoft seems to manage consistently. When installing the printer, as noted, there was no driver for the Laser Writer Select nor for the LaserJet III. Making sure that the computer is online with the internet, install the wrong printer. Literally. I picked an HP printer just for the sake of making the concept as sane as such a thing could be, but since the LaserJet III was not available, I installed an HP LaserJet Something. Crazy as it seems, go through the entire installation process to install the wrong printer. Do not bother trying to print a test page, since you know that you have the wrong printer installed and the test page will hang forever then fail. Also, in my case, since I would be sharing the printer over a network, I also made sure that the Linux print sharing network was online.
Once the wrong printer was installed, under the printer's properties option, Microsoft let me change the driver, including offering an extended online driver database not offered in the original installation process. The extended database takes about five minutes to download, but includes an HP LaserJet III driver. I could then change the driver from the incorrect driver previously installed and bring the printer online with the network.
So I'm running an Apple printer on a Linux box and installed to a Windows 7 laptop as a networked LaserJet III, installed incorrectly then partially backed out. Simple, really.
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
Proper Thinking about Computer Privacy Models
July 3, 2013
When considering computer privacy in light of recent leaks regarding NSA data collection practices, there is some sloppy thinking going on, even among computer experts who should know better. In a human sense, this sloppiness is understandable. People want to ‘solve’ a problem. The NSA is monitoring online use, people object to it, a privacy solution is implemented, problem solved.
There are a couple of benefits to this reasoning. First, people for the most part have other things going on in their lives. Birthdays, graduations, college exams, etc. They are too busy and otherwise disinclined to play ‘Behind the Iron Curtain’ with the NSA on a semi permanent basis. They want the privacy problem SOLVED once and for all. There is also the mentality of so-called ‘computer experts’. They want to provide the solution that people want. Therein lies their expertise. They do not want to admit (or do not know) that the issue of computer privacy is never truly ‘solved’.
A good example are the huge number of articles that have come out after the news of NSA monitoring broke. The Internet has been flooded with articles examining and explaining the use of PGP, TOR, OTR, whole disk encryption, etc. Implement these, goes the reasoning, and you are all set. Computer users who for the most part did not know that these products were available, can download and install them and 'solve' the privacy question once and for all.
When I wrote an article proposing a different way of looking at privacy and why the privacy question may not be so easily 'solved' it made some people very nervous. If I made any error at all, it was to assume that computer experts would understand the privacy model I was suggesting implicitly, and not require an explanation explicitly. Therefore I present the following explicit examination of a more broad and probably more realistic definition of computer privacy.
I want to begin in the Middle Ages. An armored knight on an armored horse was a formidable weapon. Armored against attack and capable of attacking, to a knight an unarmed foot soldier was vulnerable to attack, while the knight was relatively speaking invulnerable. Therefore to the degree that you had armored knights on your side in a Middle Ages battle you had an advantage that could tip the balance in war. Let's call this model Middle Ages Battle Version 1.0.
Military strategists thought about the knight and saw a formidable armored opponent on an armored horse, and saw an effective weapon to be sure, but with some curious vulnerabilities. The knight was relatively uncoordinated, physically heavy and limited in reach. A knight could not maneuver rapidly; designed to confront other knights or sweep down on unarmored foot soldiers, such maneuverability was not necessary. A knight was heavy, knight, horse and armor for both would be in excess of 1000 pounds. A knight had to be close to his enemy to strike, and being large and heavy and uncoordinated, a more maneuverable or more distant weapon defeated the knight's strengths.
So strategies were evolved to take advantage of these perceived weaknesses. If a battle could be led to or staged in a muddy field, the heavy knight could become bogged down and a new weapon, designed expressly for the purpose could be used to unseat the heavy and unwieldy knight, who could not maneuver on foot as effectively. An archer might not be able to penetrate armor at a distance, but likewise could be placed at such a distance that the knight could not reach the archers, who could decimate the opponent's foot soldiers in relative safety. The knight while unquestionably deadly, could be defeated with an evolved strategy. And that is the critical point: Effectiveness of mounted knights became unimportant once applied methodologies were in place to defeat them.
In the Hundred Years War, the English used careful observation and thinking about the nature of mounted knights to come up with these attack vectors, while the French tended to follow the old model. To apply this to computer privacy, the French believed that they had 'solved' the issue and the English evolved their thinking in the face of the old model. There are a couple of examples of evolutionary thinking about computer privacy which demonstrate the truth of this appproach.
One example comes from computer hackers. One black hat hacker writes explicitly that “As attacks become more and more sophisticated, so do hardware and software prevention mechanisms.” In the more legitimate realm, project managers call this model the System Development Life Cycle or SDLC. One depiction of the SDLC is as a process which ends in a Maintenance phase. That is, patching and fixing vulnerabilities, etc, with the major work essentially finished. Another depiction of the SDLC is as a loop, that is to say that the Maintenance phase is more than patching and fixing, it is also gathering information regarding needs, use, effectiveness and security of the current system version with an eye to development of the next system version. In other words, in this model the System Development Life Cycle never really ends.
As we saw in the Hundred Years War, the English applied this looped model of the SDLC very effectively. They did not send out knights against knights; they employed pikes and archers and tried to direct battles to muddy fields. Similarly, there is no reason whatever to assume that the NSA is ignorant of strategy. No reason except the spurious comfort that the privacy question can be 'solved' once and for all.
Let's consider this model of the SDLC in relation to the question of privacy. I wrote elsewhere in this blog about a theoretical attack that should compromise PGP on many computer systems and open those systems which install PGP to more in depth monitoring by the NSA. I developed the theory that this would be a reasonable attack on the assumption that the NSA applies the SDLC and strategic thinking in their planning. That in the face of current privacy models which they could not breach, strategic thinking would require them to find a different approach.
Since the function of the NSA is to monitor and not to destroy an opponent, the assumption of a long term and evolving strategy applies. It is not reasonable to think that the NSA, in the face of PGP, TOR, OTR, etc., simply throw up their hands and admit defeat. They do the same thing that has been validated in military history, academia and the hacking community. They employ goal oriented strategic thinking in the model of the SDLC and find a way to change the status quo. However, they would be delighted to think that nobody believes that.
Now that we have looked at motivation thus far, we can continue on and look at a couple of options as regards methods with the next section, PGP in a Security State.
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
Thoughts on the Snowden/NSA Affair
June 27, 2013
Fundamental questions are raised by the Edward Snowden affair. By this time, sufficient coverage regarding the Snowden affair is available in so many venues that I will not recount the story here, except where specific details impact an examination of some of the deeper questions this affair raises.
Did Snowden commit a crime? Speaking without legal training, it appears so. He did admit that he took a job with Booz Allen Hamilton in order to obtain national security related information which he then took without authorization.[1] It therefore seems he engaged in conspiracy and espionage. So much for the opening act. Now let's look at motives, justification and relationships, not of Snowden, who is after all only in a supporting role in this drama, but of the American government and its citizenry.
I normally object strongly to the modern tendency to excuse any act because someone else does it as well. That tends to indicate that existing in a culture of corruption somehow morally justifies the next corrupt act; it's a ridiculous and irresponsible position. However, a comparison may be useful when the same party is involved in more than one comparable act.
In 1774 the British Parliament passed the Administration of Justice Act. This law essentially said that at the colonial governor's discretion any British official charged with murder or any other capital offense could have a change of venue up to and including transfer of the trial to Great Britain.[2] This obviously selective interpretation of law was so offensive that it came to be called one of the Intolerable Acts in the American colonies. Yet another complaint about the Administration of Justice Act was that it was passed without consent of the governed. Should law not be measured by the same standards when the victimized government also selectively interprets it?
Today, American national security law is interpreted in the same manner that the British government applied in the Administration of Justice Act. At the President's discretion, which is to say, by secret executive order, the constitutional concept of privacy is selectively interpreted as or if it conflicts with executive branch privilege. The executive branch in a security state (which speaks of the Bush and Obama administrations, lest this seem partisan) has invoked executive privilege to short circuit the legal process regarding a variety of issues.[3] The President himself has said that there has to be a compromise between privacy and security[4], but has unfortunately mentioned this philosophy after the fact and after the degree of compromise has already been decided and implemented. [Another question this raises, specifically as regards the Snowden affair and national security, concerns the possibility of a fair trial for Snowden. Given the executive branch's track record of invoking state secrets privilege to the detriment of the U.S. Constitution, it is probable that any and every argument Snowden might make regarding justification would be impermissible at trial. Therefore it becomes more understandable that Snowden might be disinclined to return to the United States in the current national security environment. This is a subtlety that current press coverage of the affair does not seem inclined to consider.]
There is also the consideration of representative law. If current law is passed by representatives of the people, is that not different from the environment of the Intolerable Acts? Unfortunately it may not turn out to be the case. Granted that the legislature passed the FISA Act, that could be said to be an act representative of the people. However, when the law is extended by secret executive order and enforced nonetheless, then what 'law' is exactly becomes both unknown and not a product of the legislature. Neither this process nor the result is conducive to trust.
There are a handful of other issues to address here, for two reasons. The first reason is that I have not seen some of these perspectives anywhere else on the Internet. Nonetheless these are arguments that I suspect many people would consider. The second reason stems from the first reason: the person expressing this opinion is not without resources or effectiveness. I am speaking about a hacker known online as the th3j35t3r.
th3j35t3r has, if reputation is to be believed, hacked jihadist websites the world over, outed Anonymous members and feuded with the Westboro Baptist Church over its take on the United States military. If this is true, then we accept that th3j35t3r is technologically capable and resourceful. th3j35t3r styles himself a patriot hacker, and therefore has much to say about both the technical and national security implications of the Snowden affair.[5]
th3j35t3r mentions Carnivore and Echelon (earlier government spying programs) and the capability of commercial smartphones to monitor users. Using th3j35t3r's own source, “[i]n 2001, the Temporary Committee on the ECHELON Interception System recommended to the European Parliament that citizens of member states routinely use cryptography in their communications to protect their privacy, because economic espionage with ECHELON has been conducted by the US intelligence agencies.” (The original European report referenced in the Wikipedia article seems to be referring to intercepted fax and telephone communications as specifically regards U.S. interception efforts.)[6] However, the fact that some governments spy on citizens or that companies spy on customers in no way logically or morally justifies any one specific effort nor expansion of the practice.
th3j35t3r claims to be “aware of 40 foiled plots in just one year” as a result of programs like PRISM. The public is aware of one official who gave the 'least untruthful' answer in response to congressional scrutiny on the matter.[7] (The British said it better. In response to the Peter Wright/Spycatcher affair, a British minister admitted that he had been “economical with the truth”.) This raises questions of trust and quality of life. Trust comes into play if, as has been suggested, government has used the Internal Revenue Service to harass conservatives or has read journalists' mail. Quality of life issues include whether it is better to accept a physical security risk, or risk of political abuse of an all encompassing intelligence network in conjunction with ever more sophisticated data mining processes.
Last, th3j35t3r as a patriotic hacker, above all else supports the military, law enforcement and intelligence communities “who do the same job no matter who is sitting in the big seat.” Unfortunately, we do not know that, it is illegal to tell us that, and evidence tends to suggest that the job includes at least some degree of specialized work at the request of political or commercial interests. In this context, there are long accepted issues with the doctrine of 'just following orders'. First, we have no moral superiority in the face of hacking by other countries. Second, the examples of Nazi Germany and My Lai serve as historical guides that a soldier has some duty as regards determining whether following certain orders has a moral component. In the case of an American, this could be said to include consideration of whether certain orders are blatantly unconstitutional.
This is not to say that military espionage has no place. We definitely want to know how many planes, missiles, tanks (and computers) others have and how they are arrayed against us. We want to look to vulnerabilities in our infrastructure and to that of potential enemies, either physical or cyber. The problem comes in when or if a government feels that its own citizenry might be the enemy and targets it wholesale with its considerable espionage apparatus.
It would be a shame if the political realm can turn this affair into the Edward Snowden Show and deflect discussion of the important issues. For whatever reason it happened, it has happened. How we deal with Snowden isn't actually too important in the grand scheme of things. How we as a society deal with the issues that his actions raises is critical.
[1] Lam, Lana. “Snowden sought Booz Allen job to gather evidence on NSA surveillance.” South China Morning Post. June 25, 2013. http://www.scmp.com/news/hong-kong/article/1268209/snowden-sought-booz-allen-job-gather-evidence-nsa-surveillance
[2] Avalon Project. “Great Britain : Parliament - The Administration of Justice Act; May 20, 1774.” Yale Law School, Lillian Goldman Law Library. http://avalon.law.yale.edu/18th_century/admin_of_justice_act.asp
[3] Liptak, Adam. “Obama Administration Weighs in on State Secrets, Raising Concern on the Left.” New York Times. August 3, 2009. http://www.nytimes.com/2009/08/04/us/politics/04bar.html?ref=statesecretsprivilege
[4] Spetalnick, Matt and Holland, Steve. “Obama defends surveillance effort as 'trade-off' for security.” Reuters. June 7, 2013. http://www.reuters.com/article/2013/06/07/us-usa-security-records-idUSBRE9560VA20130607
[5] th3j35t3r. “So…About This Snowden Affair.” Jester's Court Official Blog. June 26, 2013. http://jesterscourt.cc/2013/06/26/so-about-this-snowden-affair/
[6] Schmid, Gerhard . "On the existence of a global system for the interception of private and commercial communications (ECHELON interception system)." European Parliament: Temporary Committee on the ECHELON Interception System. July 11, 2001. http://www.europarl.europa.eu/sides/getDoc.do?pubRef=-//EP//NONSGML+REPORT+A5-2001-0264+0+DOC+PDF+V0//EN&language=EN
[7] NBC News Press Releases. “NBC News exclusive: Transcript of Andrea Mitchell’s interview with Director of National Intelligence James Clapper.” NBC News. June 9, 2013. http://www.nbcumv.com/mediavillage/networks/nbcnews/pressreleases?pr=contents/press-releases/2013/06/09/nbcnewsexclusiv1370799482417.xml
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
Philosophy of Technology (Kickstarter project)
June 26, 2013
I just started my first project at Kickstarter. If you are not familiar with the concept, Kickstarter is a crowdfunding platform. In a nutshell, that means that hundreds or thousands of people pledge any amount that they can afford toward a worthwhile project, and cumulatively enough money is hopefully found to fund that project. Since funding comes from multiple sources, no one sponsor has to be found who can and will fund the entire project alone. There are many good projects at Kickstarter and some really strange and funny ones (Chthulu books for children seem to be rather better represented than one might expect). Crowdfunding is a way to get money for a project when traditional means might not be a workable option. For example...
My project (or proposed project, as it remains until or unless funded) is to write a book on the philosophy of technology. This is an important project as it provides a basis for examining the decisions we make about technology, privacy, quality of content, and more (the scope being on some level related to the degree of funding). With examination hopefully comes understanding and better decisions about why we do what we do.
I have heard of Kickstarter for years but I have never taken the plunge and joined before. It's a little scary if truth be told, but exciting at the same time. It's a little scary simply because it is a new direction for me. It's exciting because suddenly it actually might be possible to tackle my project having adequate funding to do so. I could never go to a bank and say “I want money to research, write and publish a work of philosophy.” Since such a thing would be so so pie-in-the-sky impossible, it only made sense to think about it abstractly, a daydream that we know cannot happen. It still might not happen, but imagine if it does.
With Kickstarter, I can at least pursue a dream, and it just possibly could happen. Imagine the awesomeness of suddenly being able to just do this project that really should be done, even though no commercial venture would ever fund it in their wildest dreams. I am not the only person out there with dreams, and whether my project gets funded or not, Kickstarter is definitely something I will follow from now on. There are always interesting projects and people to sponsor. The link to my Kickstarter project is here:
http://kck.st/15G37Nj
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
PGP in a Security State
June 18, 2013
PGP, or Pretty Good Privacy, encryption software for email has existed since 1991. From the time that PGP was first released, it has been under a variety of different forms of attack from an American government generally opposed to any communications that they could not read.[1] The Washington Post recently examined why, if so effective, people do not more readily adopt encryption like PGP.[2] Difficulty of use and immediacy were key concerns cited. Security of the PGP model was not seen as a cause for concern.
Since 1991, computing power has increased significantly. The 128 bit encryption standard used in online commerce has been broken in an academic setting. PGP encryption, offering the option to generate keys well in excess of a thousand bits if desired, would seem to be an as yet uncompromised method for secure email communication. That model may not be the case any longer.
For this examination we will look at several factors which may work, or be made to work in conjunction to together compromise PGP encryption. For our examination we will flesh out the requirements of a theoretical virus to handle the technical aspects of PGP compromise. We will examine the necessary properties of that virus, and determine whether the requirements to create and distribute such a virus are workable within the bounds of current technology and social and corporate access enjoyed by intelligence agencies, based on what is currently publicly known.
Cracking a PGP key in excess of a thousand bits would be a resource intensive task. It would require considerable computer power and even if a regularly reliable process, would tend to interfere with currency, in other words, it would presumably take some time to crack every encrypted communication netted using brute force techniques. Yet the focus on the security of PGP keys can also be a weakness of PGP. If your keys are secure, goes the wisdom, so are your communications. Given the focus on security of keys, let's assume that users' keys would tend to be secured, and bypass the need for possession of keys entirely, while also avoiding the resource requirements of the brute force approach to cracking encrypted communications.
PGP keys must be stored on a desktop or server associated with the user. PGP keys are identifiable by certain structural characteristics. Our properly tailored virus should scan a computer for the presence of PGP keys, wait until a piece of text is about to be encrypted or decrypted and copy that unencrypted text in the computer's buffer immediately before encryption or immediately after decryption. In other words, if the user feels it is sufficiently important to encrypt or decrypt a piece of text, the virus feels that text is sufficiently interesting to make a copy as well. This approach produces the result that the user expects to see since the PGP software itself operates normally with our theoretical virus operating externally to it, while completely bypassing any concern with possession of, or access to, PGP private keys.
Our theoretical virus developer should also infect every installer of PGP on every server that he can reach, anywhere in the world. We want to do this so that every user who installs PGP also activates our theoretical virus at the same time. We also want to do this in order to automatically put every computer which installs PGP into the NSA's surveillance net for any other use of the target computer. Several technical and legal characteristics of computer systems facilitate this attack vector.
Software installers on public servers are overall less hardened; they are made to be found and accessed. If Chinese military hackers can regularly access more hardened private servers the world over, access to relatively less secured and publicly accessible servers should be even less difficult. The best publicly available information is that the NSA has a working relationship with major software vendors which provides them with data on operating system and security software vulnerabilities unavailable to the public.[3] So our theoretical virus would more easily stay out of commercial virus scanner definition databases. Even considering that there are foreign based anti-virus providers to whom this relationship may not apply, the Stuxnet virus remained unidentified for a long time even without the cooperation of software security vendors.
If this seems technologically daunting thus far, it's not. The Stuxnet virus operated by identifying specific characteristics of the machines it was able to access, including selecting target machines by geographic region. The Stuxnet virus was both modular and an American creation, which further fulfills requirements of a dual purpose virus and ease of development. If, as believed, Microsoft and Apple are sharing information about operating system vulnerabilities with the NSA, this further facilitates development and distribution of our theoretical virus. Therefore our virus can not only capture PGP activity by the user, it also advises the virus maker of PGP activation on that local machine who can then can further fine tune aggressiveness or search criteia based on the location of the user.
Using Linux may not increase security against our virus. While our virus may not be able to effectively operate on a Linux system, end to end encryption requires the effective use of encryption software on the sending and receiving ends. In the scenario of our customized virus, if Alice runs a security conscious configuration of the Linux OS and encrypts securely, but Bob does not use Linux and is infected by our theoretical virus, the security of the communication is compromised at the decryption point in the overall transaction regardless of the security of Alice. Since in excess of 90% of the world uses an operating system other than Linux on the desktop, this is a significant attack vector. Therefore, not only may PGP be able to be compromised, it may be able to be compromised in such a fashion that a false sense of security is provided, even among users with good security practices.
In theory it would still be possible to use PGP securely even given the existence of our theoretical virus. You could use Alice for offline encryption/decryption. Alice never goes online. Bob does go online for transmission/reception. Now, how do you get the encrypted/decrypted content to/from Bob without connecting to Alice? Bluetooth, flash drives (Stuxnet's specialty) can be compromised. Connecting Alice to Bob over the network, in fact any electronic means, could potentially compromise Alice. You would have to do this:
Encrypt on Alice. Print a hard copy of the encrypt. Scan the hard copy into Bob with OCR software for transmission. For received encrypts, the same in reverse: Print a hard copy on Bob, scan onto Alice with OCR software for decryption. Of course, to prevent contamination completely, that means two scanners and printers as well.
While this might work, in practice most Americans are not likely to go to that length for security; the scenario starts to feel a bit like living in a Tom Clancy novel. Additionally, one of the key characteristics of the American model of online communications is immediacy. Intricate security processes take time to execute, which runs contrary to the concept of immediacy. Also, as above, this approach would only be effective assuming best practices on the part of all parties to the communication.
Similar models for security are suggested by more knowledgeable computer users which make use of virtual machines and other exotic configurations. As with the more extreme scenario, problems include lack of immediacy, and technical knowledge beyond that of the average end user. In addition, even knowledgeable computer experts will admit that they do not know the abilities of nation state actors, and cannot therefore, certify the security of the virtual machine model, whole disk encryption, etc.
It should nonetheless be considered that anyone involved in a criminal, terrorist, or other similar enterprise may well feel that security is more important then immediacy. Granted such reasoning, a nation state attack targeting encryption may produce false positives both in the sense that it unnecessarily captures more mundane communications while at the same time missing the most crucial ones. Thus the false sense of security regarding the security or vulnerability of PGP may apply to nation state actors as well as end users.
[1] Zimmermann, Philip. "PGP Source Code and Internals". MIT Press. 1995. http://www.philzimmermann.com/EN/essays/index.html
[2] Lee, Timothy B. “NSA-proof encryption exists. Why doesn’t anyone use it?” Washington Post. June 14, 2013. http://www.washingtonpost.com/blogs/wonkblog/wp/2013/06/14/nsa-proof-encryption-exists-why-doesnt-anyone-use-it/
[3] Wainwright, Oliver. “Prism: the PowerPoint presentation so ugly it was meant to stay secret.” Guardian, UK. June 12, 2013. http://www.guardian.co.uk/artanddesign/architecture-design-blog/2013/jun/12/prism-nsa-powerpoint-graphic-design
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
Repetitive Motion Injuries and the Computer Mouse
June 9, 2013
Repetitive motion
injuries are the product of any activity which is
repeated on a long term basis over an extended period
of time. Examples were first documented among
meat processing workers who performed the same slicing
motions over and over hundreds or thousands of times
per day, and in fact can result from any motion
repeated over an extended period of time. This
includes the use of a computer mouse over a long
period of time. I am not a doctor, and the
following should not in any way be construed as
medical advice, but I can say from personal experience
that the following provided noticeable results when I
tried it.
Several years ago, I began to feel a vague twinge in
my right hand whenever I gripped the computer
mouse. The ache, while faint, was definitely
present and did not go away during the time I was
using the mouse. The only partial remedy that I
could find was to not grip the mouse as hard, and in
practical terms, this meant not to use the computer as
effectively as I had been able to do before.
Also, being aware of the concept of repetitive motion
injuries, this did concern me on another level
entirely, namely that I knew that with sufficient
damage, should it occur, other activities with my
right hand would also be impaired, and that permanent
injury was just that: more or less permanent. So
I decided to do something about it, and in my case I
had a decided advantage.
I tend toward the left handed with fine to medium
precision work, writing, threading a needle, using a
screwdriver or tweezers, or similar activities (what I
think of as 'fine control'). I tend toward the
ambidextrous with anything heavier, carrying a gallon
of milk, driving a car, and the like (I think of this
as 'hard control'). However, there is another
area in which I am also decidedly and unquestionably
right handed, and that is using right handed tools,
such as a can opener, playing cards, and a computer
mouse as set up on most public, private and work
computers. Being a primarily left handed person
in a right handed world, I could have taken a highly
partisan approach, and bought a lefty can opener and
playing cards (yes, they exist) and demanded that
every systems administrator everywhere reprogram my
mouse for left-handed use, but it made so much more
sense to bite the bullet and learn to use the righty
equivalent available in a store near you (or
me).
So, when I began to feel that twinge in my right hand,
it occurred to me that mousing was in fact a 'fine
control' sort of task anyway and that I, as a fine
control lefty was mousing righty simply because that
was how computers tended to be set up; there was no
good reason that I should not learn to mouse
lefty.
I had one
non-negotiable rule as I began. I would not go
into the computer settings and program the mouse for
lefty button use. Like with a can opener or
playing cards, the reality is this: the majority of
computers are programmed righty and either one does
not have the systems level access to program the mouse
on a work or public computer, or it is discourteous to
reprogram the righty mouse on a friend's
computer. Instead, went my reasoning, since I
could not mouse lefty at that point anyway, and since
mousing protocol is largely social programming of the
user in any case, it would be no more difficult to
learn to mouse lefty with a righty programmed mouse
than if I did reprogram the buttons, and, without
reprogramming the buttons, I was in a position to
quickly and easily switch off on any computer anywhere
and at any time. (For this reasoning I drew on the
experiences of a couple of other lefty mousers I have
known who have reprogrammed their buttons for left
handed use, and it causes them, and people who use
their computers, no end of frustration.)
So, finally, here is what I can suggest if you are
experiencing any sort of ongoing discomfort mousing
righty as you have always done. First, see a
doctor; not being a medical man, I would not want to
suggest that you ignore that discomfort, lest a small
thing unnecessarily become a big thing. Second
literally pick up your mouse and mousepad and move
them to the left side. Mouse as normal; do not
reprogram the mouse for lefty use. That means
that you will left click with the left middle finger
and right click with the left forefinger. I find
that I wheel with the left middle and forefinger
interchangeably, but your results may vary.
During the first 24-48 hours of this transition,
promise not to email me. You will be calling me
every vile name in the book, I guarantee it.
Stick with it. After that you may email me,
because you'll say that I was right, and you'll be
calling me a genius. It works. It will be
neither more nor less difficult for you than it was
for me to use a righty can opener or mouse on a public
computer. Just do it...if you expect sympathy
from a lefty operating in a righty world, you'll get
the minimum from me...yes, it's awkward at first, get
over it. By not programming the mouse for
lefty use, you can, at will, and without enhanced
access or discourtesy to the righty computer owner
whose system you borrow, simply pick up the mouse and
move it over to the left as necessary. I say 'as
necessary', because I discovered that by mousing lefty
(with a righty programmed mouse) on systems that I
control, the twinge that I was feeling in my right
hand went away entirely. So now, in practice, I
now mouse lefty with righty programming on my
computers and righty on anyone else's computer
(although I have the capacity to switch over any time
quickly and painlessly). You can, too.
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
Tweeting
This Text and That Link (tweet2html.py)
May 25, 2013
This program is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version. This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
Enjoy!
Share this on
Deputy Level
Heads Will Roll - The Obama IRS
Scandal
May 21,
2013
Watching Fox News try
something, anything, to prove that the Obama
administration is complicit at a high level in the IRS
scandal, I have to assume that no one at Fox has ever
worked, or communicated with anyone who has ever
worked, for a living in a low level service position
in the information field. However, having had
such exposure myself, unless or until there is
evidence to the contrary, I can provisionally accept
the argument that the so-called targeting of
conservative political groups was, at least at the
operational level, and perhaps at the supervisory
level, as a function of day to day operations, neither
malicious nor politically motivated.
Let's examine a couple of actual examples from workers in one data and communications services company specifically with regard to the difference between what appears to be the policy and processes and what actually happens at the operational level. Capital P Policy certainly existed at this company, it was comprised of many hundreds of pages covering everything from billing to technical support. Since a Policy exists, therefore, goes the wisdom, there is no room for ambiguity or error. That assumption is a serious over-simplification, as a couple of quick examples should demonstrate.
In the first example,
this company's Policy stated that technicians were not
permitted to use any external resources or information
not in the official technical wiki to resolve
technical issues. Yet at the same time this
company had a new product line which was poorly
documented and on which the technical support staff
was even more poorly trained. One day a
consultant showed up from the home office and talked
at length to three specific technicians at one
site. These techs weren't in trouble, but the
home office really wanted to know how they had a 97%
resolution rate on the new product line while the rest
of the site averaged slightly under 30%.
The answer was that the in house wiki was not
sufficient or at least not well enough organized to
resolve tech support issues in most cases, so these
three technicians brought knowledge to the table
beyond the wiki, only using the wiki as one of various
resources, technically a violation of Policy since it
could result in inconsistency in the technical support
experience, whatever that means.
However, it is worth
noting that the company did not have an official
channel to suggest changes or a culture which
encouraged low level technicians to suggest changes or
to do anything except put in their workday and collect
their paychecks. There was no technical wiki
revisions point of contact, there was no way of
recording documentation and forwarding it for
analysis, and on site management was not
technologically knowledgeable. Last, in a
stringently numbers oriented production environment,
there was no time for supplemental activities such as
writing revised documentation proposals.
In the second
example, Policy said that referring customers to
outside vendors rather than resolving customer issues
directly was inefficient, frustrating to customers,
exorbitantly expensive to the company, was to be
avoided in all but the most extreme cases, and could
impact a technician's metrics, pay and their continued
employment. However as implied above the in
house technical wiki was somewhat lacking. A
handful of the top technicians addressed this
conflicting Policy by using a closely guarded process
to access a hole in the corporate firewall, through
which outside vendor websites and wikis could be
accessed. Of course, since this was prohibited,
it could not be referenced as a resource. Since
it could not be referenced as a resource, it could not
be suggested for assessment as a practical solution to
improving resolution numbers. (It should also be
noted that this scenario left a hole open in the
corporate firewall for at least a year after its
discovery, which helped the technicians even as it
left the company itself more vulnerable.)
So, in light of
certain realities in a certain type of production
environment:
- often managers manage well,
but they do not understand the actual job they
manage;
- managers may shelter behind
Policy as a function of not understanding the
technical aspects of the job;
- managers may manage based on
metrics, that is to say, they can run a spreadsheet
like nobody's business but may not understand the
underlying principles which comprise the metrics;
- Policy may not acknowledge or
incorporate tools required or actual processes used
at the operational level;
- Policy may not have a
realistic mechanism for examining potential flaws or
improvements in the Policy;
let's consider the
IRS scandal from a worker's perspective. As a
low level IRS worker, you may:
- be very aware of the above
production environment realities;
- be graded for performance reviews based on number of applications processed;
- have tens of thousands of applications to process;
- know that each application will require two full work days including all preliminary and follow up stages of application analysis;
- know that your manager will tell you weekly or bi-weekly or monthly that your performance has improved or deteriorated, and the level of that change to two management metrics decimal places;
- read the newspaper, and not be completely unaware that certain groups engaged in certain types of political activity tend toward certain naming conventions;
- find out that the data retrieval system in use (which you also understand significantly better than the managers since you use it eight hours a day and they do not) will permit Boolean searches like (“TEA” && “PARTY” OR “PATRIOT” OR “ELECTION” && “2014”), potentially reducing your workload from thousands to hundreds.
Will you, as a low level service worker, use the newly
discovered Boolean search capability to reduce your
workload, improve your metrics and generally make life
simpler for yourself? Of course you will.
Will you share how you do it with management? It
depends on the exact culture of the department,
quality of manager-worker interactions, process for
employee input, etc., but the answer might very well
be “No”.
Will management have input with regard to larger
political ramifications of shorthand in house
selection criteria? Possibly not and maybe even
probably not. Management will not know in many cases
that such a shorthand process even exists. The
actual workers do not have the same priorities as
management. Worker priorities are an interpreted
version of a corporate mission statement the same way
that management's are, but the interpretation is
different. The real problem can be traced to an
uncommunicative and overly metrics driven workplace
culture.
There is a movie from 1983 called Gorky Park, in which
William Hurt's character says that people fall into a
chasm between what is said and what is done. If
you look into that chasm, you may find that that is
where the 501(c)(4) applications all ended up.
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
Kids and Personal Responsi-woo-hoo
(on Reverse Social Darwinism)
May 19, 2013
Reading the news the
other day, that is, in a single day, I came across
these three items: one school banned birthday
invitations (on the grounds that kids not receiving an
invitation to a given party may have their feelings
hurt), another school banned honors night (on the
grounds that kids not making the grade may feel like,
well, they didn't do well enough to be included in the
honors celebration), and one municipality sent a
social worker and armed police to a home because a
parent had bought a hunting rifle for his 11 year
old. I conclude that political correctness has
run amok to the point that the resultant reverse
social Darwinism may be the beginning of the decay and
decline of a stable social society.
More than a statute of limitations ago, which is how
some of the really good stories start, my sister
taught me how to ride a bike. It went like this:
she took me to a large paved school yard about half
the size of a city block, balanced me on the bike,
explained that I must steer and pedal or put my feet
down if stopping. She gave me a running
push. I coasted along, so thrilled at the
experience of motion and focused on steering that I
forgot to pedal. I slowed and fell over.
My sister put me back on the bike, and again explained
that I needed to pedal to keep moving or put my feet
down if stopping. She gave me a running
push. By the end of the day I had swallowed two
baby teeth and could ride like the wind.
Thank you, sis, for teaching me to ride.
Unfortunately, you would be in juvenile detention
these days getting counseling while prosecutors
decided whether to try you as an adult. For that
matter, so would my eldest sister, who, on hearing
that I had swallowed baby teeth, gave me sympathy and
first aid and Wonder bread to eat, to hopefully
cushion my stomach against the swallowed teeth, and
let me go back out to finish learning how to
ride. Police, 9-1-1, counseling, prosecutors,
Ritalin and child services did not have roles in this
experience. For which, in retrospect, I am
profoundly grateful.
That day and in subsequent days I rode without helmet,
knee pads, etc. Just jump on the bike and go; I
had an ugly dog of a first bike, secondhand, tubeless
hard rubber tires with a couple of gashes in them,
dark purple with white paint splotches someone had
dribbled onto it, and it would absolutely fly, and I
flew with it. I crashed now and again, sometimes
spectacularly. I once hit a car pulling out of
an alley, and like that fabled man on the flying
trapeze, I flew through the air with the greatest of
ease, over the handlebars, and landed splayed across
the hood of the car I had hit.
This was my fault. Even at six years old, even
as I lay on the hood of the car, I expected to be in
trouble because I knew that it was my fault. I
learned to look for cars coming out of alleys.
Little emotional pang, there. It meant that I
could not completely ride like the wind anymore.
I now had to make some allowance, if only a little
one, for things like moving cars. It was called
growing up, if only a little bit, it was called (and
you should pardon the crudity, although I will try to
soften it so as not to offend) personal
responsi-woo-hoo.
That is not to say that I totally dismiss the value of
social services being more involved than when I was a
child. People who leave children in sweltering
cars, as an example, should have the police
involved. But somewhere there is a line between
protection and protection to a fault. I am not
nearly invested enough in child raising to know
exactly where that line lies, but I do know that at
some point children will have to fall down and bang
themselves up, not get invited to a party or make the
honor roll. And that's okay; it's learning in
little ways that the world is not perfect. It
prepares the adults that they will become for learning
that the world is also not perfect in bigger ways:
there is poverty, there is war, they might get turned
down for a prom date or a job, or have their loan or
college application rejected some day; well prepared
for these unfortunate events, they will pick
themselves up and move on; poorly prepared, they can
look forward to counseling and an anti-depressant
prescription as they try to make sense of a
socio-emotional paradigm that makes no sense.
I do know that should I ever find myself on trial for
something some day, I would simply not be able to say
with a straight face how falling off of a bike without
knee pads or not getting invited to a birthday party
had so traumatized me that I did X. I simply
could not say it and keep a straight face.
Falling off of the bike, not getting invited to the
party, were simply part of growing up, and I am
reasonably confident that, given the opportunity to do
so, kids these days would take these rejections in
stride and not become felons as a result. There
is even the potential for a reverse political
correctness effect in later years; that is, the
children who are not allowed to learn in little ways
that life is hard sometimes will resent that they were
not allowed to learn that lesson as a child, when the
penalty was less.
Finally, I can conclude that personally, witnessing
the political correctness minefield parents must
navigate these days, I am soooo glad that I chose to
not have children.
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
Learning New Subjects on the Cheap
May 18, 2013
One of my discoveries
regarding learning some (and I do stress 'some') new
tech skills is to buy a used manual a couple of
versions old as my first exposure to the tech topic in
question. One time, looking to explore the Python
programming language for the first time, I looked to
see what was out there and found the following:
- Oreilly.com had the latest version Python manual for $45 plus any tax, shipping, etc.,
- eBay had a (C)2007 version for $10 delivered.
- I got the (C)2008 epub for $5 from Android Market (on a 7" tablet and I exported a copy to PC, so no, I was not squinting at a phone in the interest of cheapness).
Some printed manuals I have bought in the past appear
to have never even been opened...probably the vendor
could not move version x after version y came out. It
sounds strange not getting the cutting edge version
(especially for a topic like technology), but it
actually makes sense in some cases and with some
stipulations. Consider...
- I was learning something new,
so would have some work to do to get up to speed
anyway. I was not ready for or going to miss
cutting edge yet. Content structured for
learning was more valuable than unstructured cutting
edge content as a first exposure.
- Some very, very few things in a manual 2-3 versions old will be out of date; most things covered will not be.
- I could use online documentation to get up to cutting edge once I had the basics down. Continuing with Python as the example, online documentation is extensive, but not necessarily organized with a new learner in mind. This is not surprising for two reasons. First, online documentation comes from a variety of sources and users, and there is not necessarily agreement on any specific formatting or organization of that documentation. Second, there is a truism regarding programming, that the better the programmer the more lousy they are at documentation. Therefore one might be grateful that anything is available at all, and understand that the multitude of contributing programmers will not feel compelled to format the documentation with a learner in mind.
The same conceptual model also applies to other book
topics on languages, the arts,etc. As an
example, I recently downloaded a talking book from librivox.org
on the topic of the Middle Ages. The copyright
date was 1906, but the history of the Middle Ages has
not changed since that date (although it must be
admitted that current interpretations of that period
may well have changed, and a greater depth of
information may have come to light since the book was
published). These caveats notwithstanding, the
book is a useful summary of major Middle Ages people
and events.
When I was in high school I was browsing in a book
store and found a used college level Psychology 101
textbook for $2. I found it interesting enough
reading to be worth the price so I bought it.
Later in college, where Psych 101 was a required
course, I found to my amusement that the $2 book I had
bought followed the college course almost perfectly
lesson for lesson even though it was a completely
different title. It also saved a struggling
college student the $50 “official” textbook price.
There are specific exceptions to the usefulness of
this model, especially as regards technology
subjects. For example, wifi security standards
have changed rapidly over the years, so that a book on
wifi security from 2004 may be less useful than a
circa 1900 history book. This exception does not
disprove the model, rather, it simply means that
currency of the subject matter and the subject itself
must be taken into account. If you feel that you
can make that intellectual adjustment, getting your
feet wet in a new subject area with an older text
might make economic sense.
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
The End of Life (of Windows XP)
May 05, 2013
Windows XP is scheduled to reach end of life as of April 8, 2014. What that means in practical terms is that you will really have no choice other than to upgrade your operating system. Also, since all but more robust machines currently running Windows XP will not meet minimum requirements for later Windows versions, you will have no choice except to upgrade your computer hardware as well.
At one time, Microsoft used an obnoxiously aggressive approach to making you want to upgrade Windows. A few years ago I came across a used HP 2300c scanner. There was no driver CD for Windows (Windows 98 at the time) included with the unit. So I went to HP's website to download the driver. This was a normal and customary approach when trying to install resale hardware, since very often driver CDs had been lost or damaged. Instead I came across a one page apology from HP which ran essentially thus:
-
The Windows 98 driver for this product includes some Microsoft copyrighted code.
-
Microsoft refuses to continue to let HP distribute their copyrighted piece of code in the form of this driver.
-
Therefore HP can no longer offer a Windows 98 driver for this device.
Microsoft had just decided to pick up its toys and go home. So the reasoning went that you don't have to upgrade to Windows XP, but Microsoft will do more than passively end support for the current operating system; Microsoft will in fact actively interfere with third party support until you want to upgrade. Since Microsoft has used this approach before, it must at least be considered that Microsoft could do it again. However, in point of absolute fact, this approach may no longer be necessary for Microsoft today, and if used at the end of life for Windows XP, may be only incidental.
Today, that obnoxiously aggressive approach may be replaced by an obnoxiously passive approach. The reality is that the Windows operating system of today is so amazingly famous for security flaws that the phrase Patch Tuesday actually entered the modern vernacular as a result. In light of this reality, it seems probable that within a month or two of end of support, there will be so many exploitable unpatched security flaws in Windows XP that it would be foolish to continue to run it. This, then, seems to be the inescapable if somewhat astounding conclusion: By the very fact that Microsoft Windows is laden with security problems, by ending support, Microsoft virtually guarantees that people will upgrade their operating systems and thereby generate revenue for Microsoft. It could actually be said to be to Microsoft's benefit to bang out an operating system so in need of patching, publicize it to the point that their patches become a punchline, and then decline to provide those patches.
However
you feel about that, the reality is that your
computer will need to be replaced if it cannot run
the next Windows version. This unfortunate reality
in mind, now would
be a good time to start to assess your replacement
options. For you, this may mean acquiring a
Windows 7 machine while they can still be had,
trying Linux or budgeting for a Mac. That will
mean some research. Here are links for beginning
to research Linux and Apple. Another Windows
computer is not the only option out there:
Share this
on ![]() witter or
witter or ![]() acebook.
acebook.
Latency Defined
Mar 21, 2013
Latency (lā tĕn sē) n. 1 The technical term for your data connection being slow 2 slowness
Latency, as a term, has the benefit of sounding technical. When customers hear latency, and they pronounce it to themselves, they taste the word if you will. They memorize it, so that they can repeat it to others, as in: “My ISP has detected latency in the area.” People with whom they share this tidbit will nod sagely, and perhaps memorize the word for later use themselves.
Even technical people are not completely immune to this tendency to some degree. We understand that latency means slowness, but also know that latency can be caused by anything from bandwidth issues to technical glitches or outages; most importantly, when we hear latency, it means that by use of the term, the service provider has identified and is addressing the problem. There is no specific reason to believe this last clause, as no part of the definition of latency even remotely suggests a resolution. However, the technical and non technical alike tend to give the provider additional leeway to address the issue when we hear latency used correctly in a sentence.
Slow has a different connotation altogether. If your ISP tells you that connectivity is slow in your area, you may be a sucker for not getting compensation for the slowness, you will be upset at the very least, and you will demand action from the ISP to fix it. Preferably yesterday.
Thus word choice itself suggests additional credibility, competence, efficiency, regret at the inconvenience, etc., on the part of the party using the word. Or, to be completely accurate, the customer, upon hearing latency, suggests these additional qualities to themselves without necessarily having any justification whatever for the addition. Or, to quote the famously quotable Humpty Dumpty, “When I use a word, it means just what I choose it to mean – neither more nor less.”
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
Women's Magazines: In a Checkout Line Near You
(for International Women's Day, March 08, 2013)
Any man who says that he understands women is either lying to you or lying to himself. I say that as an introduction to observe that possibly the following makes a great deal of sense to women and I am simply missing the point. I admit that possibility up front. But, what I saw still strikes me as a little, well, weird. Listen...
Standing in line at the grocery checkout is the great equalizer. Maybe that is linked to why the people are so upset when a politician cannot say how much a gallon of milk costs; you just know that the politician in question has never been in the checkout line, a captive audience to lip balms, candy bars, breath mints, energy drinks, AA batteries, Bic lighters. And women's magazines. And that's where my story today begins.
I was standing in the checkout line, a little distance back from the endcap (that is what marketing people call the island of impulse products which runs from the cashier, back a couple of feet, around the front and down the other side into the next checkout aisle, in marketing speak, the endcap) and I could see, on the front of the endcap, the covers of three different women's magazines. Each of the three distinct magazine covers was split between diet tips and cupcake recipes. Diet tips, cupcake recipes, diet tips, cupcake recipes, diet tips, cupcake recipes. All three magazines. I thought, “Hmmm.”
As the checkout line progressed and I moved up in it, I came to the side portion of the endcap. This time four more, completely different women's magazines, no duplication of one another, nor of the original three titles. Diet tips, cupcake recipes, diet tips, cupcake recipes, diet tips, cupcake recipes, diet tips, cupcake recipes. Seven, count 'em, different women's magazines, the covers split between advertising diet tips and cupcake recipes.
By then I was thinking, “Okay, here's your diet tip: Don't make the cupcake recipes!” But the reality is that seven different magazine editorial boards approved these seven distinct covers and issues, presumably because they would sell. It seems to me that either the media industry, or more likely, economic society in general, makes money running women in circles, as each part of the circle represents economic activity, even if it is at the expense of the consumer herself. Women, in the meanwhile, must be running around the circle until they don't know which end is up. Diet tips, cupcake recipes, diet tips, cupcake recipes, diet tips, cupcake recipes.
The good news is that there is hope, once the model has been perceived. A woman I shared this anecdote with tells me that since I told it to her, she now notices the diet tips/cupcake recipe format repeated endlessly on wonen's magazine covers. Once seen, it cannot be unseen. And that's a start. With perception comes a pause for thought and informed decision as opposed to conditioned responses. Maybe you like the diet tips, maybe you like the cupcake recipes. So be it. Either is fine as long as you know why you do it.
Or am I missing the point entirely?
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
Get some SeaMonkey
Feb 26,2013
In the beginning there was Netscape Communicator, and geeks saw it and said, “It is good.”
Netscape Communicator was the full browsing suite. It included Netscape Navigator (the browser), Netscape Composer (a decent GUI HTML creator and editor) Netscape Mail (for POP and MAPI accounts), and an IRC chat client. Mozilla forked development of Netscape Navigator (just the browser) into the Firefox browser of today. Netscape Communicator (the suite) became SeaMonkey. It is alive and well and updated at the SeaMonkey Project web site.
There are a couple of reasons to have SeaMonkey in addition to Firefox. I say in addition, because I have both of these packages on my computer and use them both, sometimes simultaneously. Let's say that I have a Kindle book open in Workspace 2. I have it opened in SeaMonkey. Compatibility is not an issue since SeaMonkey uses a Mozilla browser ID string and Amazon likes it just fine. In Workspace 1, I may use Firefox to pay a bill, and common wisdom suggests closing the browser when finished accessing sensitive sites. If I had my Kindle book open in Firefox, I would also have to close that; with the Kindle book open in SeaMonkey I can open and close Firefox as often as I like and SeaMonkey is not affected.
Firefox bookmarks are compatible with the SeaMonkey browser. In Firefox, go to Show All Bookmarks and Back Up your bookmarks. This saves a copy of your bookmarks in a file with a .json extension locally (on your computer) or even in a network drive (for restoring onto a different computer like a laptop). In SeaMonkey, go to Bookmarks, Manage Bookmarks, Restore and point to the .json bookmarks file you just exported from Firefox. Your Firefox bookmarks are imported including special bookmarks toolbars. (By the way, if you have a lot of bookmarks, even if you do not choose to use SeaMonkey, backing up your bookmarks somewhere on occasion is still a best practice.)
SeaMonkey Composer is a quick and easy (and free) GUI for editing HTML web pages. Often the quickest and easiest way for me to update this blog with reliability and consistency, that is, I can quickly add a post and not have to worry about losing formatting on the page overall, is to bring it up in SeaMonkey Composer and drop in my copy.
Because the SeaMonkey browser string identifies the browser as Mozilla, more often than not Firefox plugins will work. Even when that is not the case, even limited application like an independent Firefox compatible second browser and HTML editor GUI make it worth having. Just leave Firefox as your default browser and manually open SeaMonkey alongside when you need it for special tasks.
As a computer geek, I liked the full browser suite that was Netscape Communicator more than I liked the stripped down version which became Firefox, and I am happy to see that Communicator survived. Get some SeaMonkey here: http://www.seamonkey-project.org/
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
They've Ruined Ludwig V!
Feb 25, 2013
A lighthearted post today. I am listening to Beethoven as I work on the computer, and I find that I can sympathize with Alex, the protagonist of A Clockwork Orange.
When I was a child in Chicagoland, Sunday morning network television in a certain time slot was limited to choices of Mass for Shut-ins, Meet the Press, or The Magic Door (kind of like Sesame Street for good little Jewish boys and girls). Now, I am not Jewish, but I was a kid, and with the choices available, The Magic Door was the winner. The thing is, I did not know that the theme music (Open, come open, the magic do-or with meeee...) was scored to Beethoven's Sixth. Now, thanks to that show, every time I hear the Sixth, I think “They've ruined Ludwig V!”
Real horrorshow, oh my brothers!
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
HOWTO: Blackberry as Bluetooth Modem in Linux
Originally Published Jun 7, 2011 at Yahoo! Associated Content
Tethering is using your smartphone as a modem to get data to your personal computer. If you happen to love the Blackberry, and run a Linux box, there are ways to tether in Linux.
The first way is with a freeware (although donations are accepted) product called berry4all. I mention berry4all because it does work. It's tricky and kind of geeky to set up, but it works as advertised. Also, if you want to practice tweaking your Linux box, this is the way to go. And it does require tweaking; berry4all is made for all mobile providers equally, and you can either modify an existing script from the website (www.berry4all.com) or write one from scratch for your mobile carrier.
The point of berry4all is twofold: it allows you to tether in Linux or Mac, which Research in Motion most definitely does not support, and it allows you to do it plugged into a USB port. Berry4all is the middleware between dial up networking and the proprietary Blackberry modem mode. I have set it up in OpenSuse and Fedora Linux and both work just fine, but be prepared to spend time tweakin' and readin' and readin' and tweakin'.
Recently I found a better way. For another purpose entirely, I acquired Bluetooth dongles for a Fedora Linux tower and Ubuntu laptop. These were no name, Chinese, swap meet quality, dollar-fifty Bluetooth dongles of no technological significance whatsoever -- they do not even show a name in the system specs of the computer, but Linux sees them just fine.
With Bluetooth dongle installed, pair the Berry to the Linux box. This is fairly intuitive in today's Linux assuming that you have ever paired two Bluetooth devices. Next go to Network Manager (or the equivalent for your GUI and distro). You've possibly never been here before: Linux found your Ethernet when it installed, and you never looked for more connection options. But there are more: There are VPN, DSL and Mobile connection options; you want Mobile connection, of course.
To create the Mobile connection, you will need the sign in information (if any) from your mobile provider. Even if you are not going to use berry4all, the website is a good resource for this information. Enter the required information for a dial up connection in the Mobile connection fields. In the Blackberry itself, go to Options > Bluetooth and make sure that the pairing connection to your Linux box has the modem option enabled. By the way, you specifically do not want to plug the Blackberry into the USB for a Bluetooth modem connection.
Connect with the new Mobile connection you created and you're online. The entire setup takes about two minutes, is actually easier to create and use than using Blackberry Desktop Manager in Windows, and it has the side effect of giving you a cool unwired Mission: Impossible look when you tether. But don't blame me if you walk away with your laptop and forget the Berry.
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
Mandiant on Advanced Persistent Threats
Feb 19, 2013
If you have not read the report on Advanced Persistent Threats (APT) from cyber security firm Mandiant, you should. Not too techie and interesting reading. Mandiant admits that it does not have conclusive proof, but does present enough evidence to strongly indicate that the hacker group Mandiant refers to as APT1 is either a Chinese military cyber unit or that there is a Chinese hacker group in the same geographic area as the army's cyber unit, operating under the noses of the Communist Party without their knowledge and with the same goals as the Chinese military cyber unit. Pick one.
One point in the report which I found interesting is that even the most advanced hackers can make elementary mistakes, which can be tracked by a careful analyst. A Mandiant video appendix to the report suggests that one Chinese hacker appeared to give his own mobile number for verification of a new email account. I'll not be the one to give instructions on how to do it, but any hacker who cared to could register an email address (even one which required phone verification) without giving out their own phone number. That's to say nothing of the many email providers which don't require phone number verification.
Another
point to note is that what you say and do online is
forever. According to the Mandiant report,
during an online Q&A several years ago, another
of the Chinese hackers registered to chat with the
speaker. That old record left enough of a trail to
track the occasional footprint of this hacker and
led to tying him to APT1.
Maybe
the most important point of all is this:
Nobody should be shocked or stunned that the Chinese
have the equivalent of the NSA or GCHQ. Fine,
that would be expected. The problem that
people have about Chinese cyber capabilities is not
that they exist, but in how they are used. The
Mandiant report says that Mandiant can document that
the APT1 unit has stolen over 6 terabytes of data
from computers in other countries since it has been
operating, much of it commercial in nature.
If
that is so, then military cyber capability is not
the problem. Armies have always wanted to know
what other armies are up to and are capable
of. You don't have to like it, but you should
at least expect some degree of military
espionage. The problem is aggressively using
that cyber capability for commercial espionage,
which on some level is less like espionage and more
like warfare.
Read the entire report at http://www.mandiant.com/apt1
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
To Linux or Not to Linux
Feb 17, 2013
As is obvious from other items in this blog, I run Linux on one of my computers. In the interest of full disclosure, I also run Windows 7 on another. Linux users in general are asked to advocate for Linux whenever possible and generally take this request to heart. In this entry I will examine whether to use Linux or Windows and why. What I will not do is advocate without thinking it through. I will, as this entry goes on, consider elements to be added to a complete statement regarding requirements necessary to opt to explore Linux.
I have heard the analogy (although unfortunately I cannot recall the source) that Windows is to an automatic transmission as Linux is to a manual transmission. It is an excellent analogy, and is a good jumping off point in a comparison. Like an automatic transmission, Windows performs relatively well in most conditions, and is relatively easy to use within its limitations. Like a manual transmission, Linux requires more knowledge or willingness to learn, outperforms Windows, and is easy to use if and only if the effort has been made to learn it properly. Because Windows is made for a user base of varying technical knowledge, many aspects of configuration fine tuning available in Linux are not available in Windows, and in the subsequent fine performance difference one sees the truth of the automatic versus manual transmission analogy.
I have read that the eventual goal of Linux is that it should be easy enough to use that your grandmother can use it. Interestingly enough, I personally know a grandmother who uses it. With significant limitations. Briefly, here is the story:
This person was using Windows and would, on a fairly regular basis, cause the blue screen of death or have entire packages of software completely disappear, or click on website links thereby installing no end of spyware, malware, etc. I would, on a fairly regular basis, be called on to clean up the current problem and make the computer whole again. Finally in the interest of my own continued sanity, I installed Linux on her computer instead. I have the admin account, she has a user account. The computer has been running smoothly, without crashing, installing viruses, or losing entire software suites, etc., for around two years as of this writing.
Her computer does anything that she requires of it. Various Linux boxes I have set up can and do use the web, Open Office, email, laser printer, bed scanner, webcam, wifi and Bluetooth dongles, cordless mice, CD/DVD burner, TV tuner card, multimedia card reader, file and printer sharing over wifi, and smartphone as Bluetooth modem. So this grandmother does not lack for functionality, but also explicitly does not have access to admin functions. And that last is an important distinction.
A truly complete statement regarding the utility of Linux for the average user might be something like: Linux is sufficiently easy and functional enough for your grandmother to use and is more stable and secure than Windows provided that she has a user only account, is locked out of admin functions, and has a knowledgeable resource available to update the Linux box, assess hardware and software requirements and implement them accordingly. In all fairness, a truly complete statement regarding Windows might be something like: Windows is sufficiently easy and functional enough for your grandmother to use, but by default gives her the sufficient access to damage or destroy the operating system, is more vulnerable to attack for the same reason that it is easier to use, has greater hardware and software support, but ideally would still have a knowledgeable resource available to assess hardware and software requirements and implement them accordingly.
So, finally, since there are benefits and drawbacks to both Windows and Linux, do I advocate Linux or not? For end users, the answer is 'yes' if and only if there is a knowledgeable admin to originally set up and maintain the Linux box on an ongoing basis. If that admin does not exist, then I suggest Windows since it has a far greater technical support base. For knowledgeable users themselves, I will go back to the transmission analogy and suggest a test drive. There are three ways to test drive Linux without completely abandoning Windows.
One, if you have one, use an older outdated machine which will not run the current version of Windows. Put a lightweight version of Linux on it and you can get several more years of use out of that older machine. A good lightweight option is Mint Linux. Optionally, buy a cheap laptop, making sure that it includes a Windows recovery CD. Install Linux (which will wipe the Windows install) and if desired later, use the recovery CD to wipe Linux and install Windows again.
Two, install a dual boot. To create a dual boot you generally boot an existing Windows computer with a Linux install CD or DVD. The installer detects Windows and offers a dual boot option. From then on, when the computer boots up, you have the option to continue with Windows or Linux for that session. With a little tweaking, your documents, pictures, videos, music, that is, user content, is generally available to either Linux or Windows. The downside of this method is that removing a dual boot if desired later is a technically involved and potentially dangerous process. In other words, if you are not really computer savvy, you may be stuck with it. Also, with a dual boot, applications software installed in the Windows portion is not easily available (or in most cases, available at all) to use when booted in Linux and vice versa.
Three, test drive Linux in a virtual machine. A virtual machine means that the virtual machine software reserves a user selected portion of the computer's resources to create a computer within a computer. So that if your Windows PC has 8GB of RAM and 250GB of available disk space and a duo core processor, you can allocate (tell the virtual machine software) to give 2GB of RAM, 100GB of disk space and one processor to the virtual machine. Then you run your Linux install CD as normal when the virtual machine starts up. The plus sides of this approach are that you can remove the virtual machine completely if desired with relative ease and that you can try more than one flavor (called a distro or spin) of Linux without changing your Windows install. As with a dual boot, you can, with a little tweaking, access your user content on the Windows side, but not Windows applications software from within the virtual machine. The downside is that you want to have a relatively powerful PC to run a virtual machine sufficiently well as to get an honest picture of how Linux operates. The figures of 2GB of RAM, 100GB of disk space and one processor are probably the minimum that should be available to a virtual machine. A bonus of this method is that if you upgrade your PC memory or processor to run a virtual machine, that memory and processor are available to Windows when the virtual machine is not running. Easy to use (and free for home use) virtual machine software is available at www.virtualbox.org
So, yes, with certain limitations, for knowledgeable users I do advocate at least giving Linux a try if you need a secure and stable multi-user system, want more performance options, are willing to learn, or already administer systems for others. If these conditions are not true, Linux may not be for you.
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
Examining Technological Vulnerability
Feb 16, 2013
Hurricane Sandy is a good opportunity to examine our expectations regarding the stability of technology. “Expectations” includes the assumption that the technology will always work. In other words, we think about the quality of application A versus B or device C versus D but the underlying assumption is that the underlying data networks will just work. As Hurricane Sandy and other natural disasters indicate, this assumption of uninterrupted and reliable service is dangerous and unwarranted. And this model extends further, and points to the vulnerability of data systems to terrorism and cyberwar.
To examine this vulnerability a couple of example should suffice, with a hurricane as catalyst. For a mobile phone to work, the phone must be charged, which requires electricity. The cell phone reaches out to a cell tower, which also requires electricity to operate. To handle increasing bandwidth requirements in the most cost effective manner, mobile providers are increasingly routing mobile data, SMS and voice traffic through the internet. This requires electricity and data connectivity. If any of these elements fail, connectivity fails, and the assumption that mobile data and voice will be available is not met. Proprietary services such as Facebook, Twitter or Blackberry mail add additional connectivity requirements.
Another example is voice over internet (VOIP) telephone service, the best known example of this service type is Vonage. For a VOIP connection, there must be web connectivity and electricity. Both of these elements must be present uninterrupted from the customer to the area outside of the service interruption. To add to the qualifications, the area of service interruption is not static. In other words, an electricity outage may cover one area and have a certain duration, while a data outage may impact a different but overlapping area and for a different time duration. Yet without these elements all working, a service which requires all of these elements fails.
Increasingly in the Information Age, communications is built on a model in which one fragile element is delicately and gently balanced on top of another. A digital house of cards if you will. If one of the cards at the bottom falls, the entire house can come crashing down. Easily, quickly, a lot more readily than expected...until a natural disaster steps in to remind us just how fragile the house of cards is.
In a way, this is market forces at work. The primary goal of a mobile or other data provider is to bring products to market and show a return on investment, and as quickly as possible. This may mean retrofitting an existing system to add new capabilities rather than building from the ground up (consider, that decades after the rest of the world has gone metric, the United States still builds cars, roads, machinery, etc., using inches, feet and miles). This may also mean not building for redundancy (it would not be cost effective to have generator backups on every cell site everywhere).
However, in the case of a widespread natural disaster, or a terrorist or cyberwar attack, having a relatively limited number of paths to connectivity dramatically increases vulnerability. While an event such as a hurricane is never wished for, it is a good opportunity to ask some relevant questions about this vulnerability.
What elements are necessary to uninterrupted
connectivity?
What alternate processes or technology can be employed if the primary fails?
How many levels of redundancy are needed to insure connectivity?
What systems are critical and in what order should connectivity to these systems be insured or restored (as technology evolves this answer is subject to change, so that Twitter may be more critical now than it was a year ago, etc.)?
Are the same elements equally
vulnerable to different sorts of interruptions
(would China or Iran attack the same parts of
a system that a hurricane would disrupt)?
Once these questions have been
established, a regular review and update is in
order as technology evolves (what is true
today will not necessarily be true tomorrow).
Development of any effective and
successful system is an ongoing
process. The lessons we can learn from
Hurricane Sandy can be an effective
step in that process.
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
HOWTO: BOINC in CentOS Linux (the easy way)
Feb 16, 2013
This
HOWTO describes the quick and dirty way to run
BOINC in CentOS Linux 6.3. As the man says, your
results may vary, but I'm running BOINC with BOINC
GUI as I write this. I did it the way that I
did for several reasons: a search of the web
for BOINC in CentOS, plus the error messages I
received trying anyway, plus having done something
similar in Fedora Linux strongly suggested that
this was the easiest, quickest way to do it.
BOINC,
in case you are not familiar with it, is a
distributed computing project. In a
nutshell, that means that extremely data intensive
and (mostly) worthwhile if underfunded projects
have more data to crunch than they have available
computing power. Think along the lines of
looking for artificial non random patterns in
radio telescope data for SETI (an unabashed plug
for my favorite BOINC project) or breaking down
the human genome. In either case, a lot of
data to analyze. So the question then
becomes where to get the excess computing power
needed to look at all of this data. The
answer is distributed computing.
In
distributed computing, a large data set is broken
down into packages that a personal computer can
handle. For example, an hour of radio
telescope data may be broken down into thirty
two-minute packages which a personal computer can
analyze easily in a reasonable period of
time. The end users' computers contact the
BOINC server which sends some of these smaller
packages of data to the personal computers of
thousands of users. These personal computers
analyze that smaller data set when the screen
saver is active, when the computer is idle, or any
combination of specifications the computer owner
sets. When finished crunching the data set,
the personal computer reports only the result of
the data analysis to the BOINC server. Since
people tend to leave their computers running these
days, this is a good way to use those extra unused
computer cycles.
Specifically
regarding the instructions below, Linux purists
insist that the Linux version is best just because
it is, however having gamely wrestled with
permissions in the Linux version which appear to
be poorly documented or even understood as regards
BOINC, I am forced to disagree. If and when
the Linux version is ready for prime time, I will
be glad to give it another shot. In the
meanwhile, BOINC in Wine can be up and running is
a couple of minutes, as follows:
Install Wine (yum install wine)
Install SELinux Policy Editor (yum install policycoreutils-gui)
Do System > Administration > SELinux Management
Under Process Domain, make the BOINC policy permissive
Go here: http://boinc.berkeley.edu/download_all.php
You are
downloading BOINC for Windows version 5.8.16
32-bit. NOTE: do not get a later version
than 5.8.16 even though they are available. Doing
so makes CentOS kick out the installer with a
domain controller error. Also, one of the first
things the BOINC software does is update itself
anyway, but it does it internally, and does not
get errors from CentOS.
Run the
installer in Wine. Accept all defaults except
uncheck the installer options Start on Boot and
Make Default Screensaver options since they won't
work anyway and may cause issues.
Make and
save a BOINC boot script file much like this:
#!/bin/bash
cd "/home/myhomedir/.wine/drive_c/Program
Files/BOINC/"
wine boincmgr.exe
Do
System > Preferences > Startup Applications
Add an
entry for your BOINC boot script
To
connect to a BOINC project you may have to fiddle
with BOINC Manager at first to get it to go
online. Fiddle under Advanced View > Advanced
> Select Computer and enter localhost as the
computer name.
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
Nintendo Lives!
Feb 15, 2013
Back when I was an Earthlink customer, they sent out a weekly email newsletter of interesting links. One such link was to a package of NES ROMs and an engine to run them (in Windows 9x at the time). Computers and software have changed and the Windows 9x engine is no longer practical, but the NES ROMs got backed up and I recently found an application to run them on a modern Linux box.
For those who do not know, an NES ROM is a computer program. Each NES ROM is one video game originally made for the Nintendo Entertainment System. Generally these files have an .nes extension. Driven with the proper engine, you can run a video game which looks and sounds just like the video arcade version from back in the day. I could not tell how many quarters went into Donkey Kong or Burger Time or Galaga machines when I was in high school, but it was a lot. Now, I can take a quick break with one of these games any time.
The program I found is fceuX 2.2.0 at http://fceux.com. Installation is a little out of the ordinary, using an installer called scons rather than Red Hat Package Manager (RPM) format. However, the included documentation provides explicit plain English instructions for installing via scons. Altogether it took under 10 minutes to have fceuX running in CentOS Linux including installing scons.
This does point out a useful concept, that of package backups. As a best practice, when you download a package, and have installed it and are happy with it, back up the original package. Burn the installer to CD before you delete it. If the installation was unusual, make some notes about what you did and ZIP them with the installer. You may not touch it for years after that. But when you ask yourself if you didn't have a font or an icon or an NES ROM once, the answer will be 'yes'.
Now if you'll excuse me, I gotta go get a soda and some more quarters...
Share this on
HOWTO: Install WinFF with full features in CentOS Linux 6.3
Feb 14, 2013
This
is a fairly basic HOWTO, but it resolves a couple
of potentially important issues, specifically the
tendency of Linux distros to exclude formats which
might not be completely copyright free as this
tendency applies to ffmpeg (and consequently
WinFF) and how to fix the error libvo_aacenc not
found (to which seemingly infinite forum posts are
dedicated).
Being frustrated that WinFF in Windows XP will convert a video to MP4 suitable for an Android tablet, Blackberry, etc., and WinFF in CentOS6 will not, I came up with the following changes to remedy that situation. WARNINGS: This works on my CentOS6 box, and I cannot guarantee it will not cause your box to melt into a heap of molten slag. Being a video noob, there are probably things I did poorly or were unnecessary. That in mind, here is what I did...
Install the Redhat package vo-aacenc-0.1.2.tar.gz to permit aac encoding from here: http://sourceforge.net/projects/opencore-amr/files/vo-aacenc/vo-aacenc-0.1.2.tar.gz/download Follow normal ./configure, make, make install process.
Compile and install ffmpeg-1.1.1.tar.bz2 from here: http://ffmpeg.org/releases/ffmpeg-1.1.1.tar.bz2
NOTE: Do not uninstall any version of ffmpeg CentOS currently installed since that will impact about a dozen already installed packages.
NOTE: The ./configure step here is repetitive, intensive and tedious. It works like this: I used the configure line:
./configure --enable-libfaac --enable-libx264 --enable-libmp3lame --enable-pthreads --enable-gpl --enable-nonfree --disable-crystalhd --enable-gnutls --enable-libcdio --enable-libdc1394 --disable-indev=jack --enable-libfreetype --enable-libgsm --enable-openal --enable-libopenjpeg --enable-libpulse --enable-librtmp --enable-libschroedinger --enable-libspeex --enable-libtheora --enable-libvorbis --enable-libx264 --enable-libxvid --enable-x11grab --enable-avfilter --enable-postproc --disable-static --enable-shared --enable-gpl --disable-debug --disable-stripping --shlibdir=/usr/lib –cpu=i686
This will fail many times. Each failure will give a specific error such as libvorbis not found or libspeex not found, etc. Each time, install the base package AND the -devel package corresponding to the error message. So with an error libvorbis not found, install libvorbis and libvorbis-devel. Continue to do this until all required packages are installed and ffmpeg configures correctly.
The new ffmpeg installs to /usr/local/bin/ The old CentOS installed ffmpeg is in /usr/bin/ Rename the ffmpeg executable in /usr/bin/ to something like ffmpeg.old and add a link from /usr/local/bin/ffmpeg to /usr/bin/ffmpeg (you will need root access for this). Optionally, once you have installed WinFF in the next step, you can also go to your /home/yourname/.winff/ folder and edit cfg.xml to point to "/usr/local/bin/ffmpeg" instead (Leafpad is a good editor for this).
Install the WinFF Redhat RPM called winff-1.4.0-3.i386.rpm from http://winff.org/html_new/downloads.html
WinFF in Linux will not offer the full range of video conversion options. So fix that manually. Use the WinFF presets here: http://winff.googlecode.com/files/presets-libavcodec54_v1_libfaac.wff and instructions for inserting presets here: http://code.google.com/p/winff/wiki/InstallPresetsxml
Test a conversion in WinFF. It will likely fail with an error referencing the audio encoder libvo_aacenc not found. Fix it like this: in your /home/yourname/.winff/ folder copy presets.xml to presets.xml.old, and edit presets.xml thus: replace every instance of -acodec libvo_aacenc with -acodec libfaac You can leave everything else as-is. Save and exit. Run WinFF and convert a video (Blackberry Curve Fullscreen and Google Android Compatible options tend to make standard MP4s as far as I can see, so you can test with those).
You're done!
Share this on
The Age of the Technology License?
Originally
Published August 16, 2011 at Yahoo! Associated
Content
Flash
mobs in Philadelphia and riots in England had
one new element in common: They used mobile
technology to coordinate criminal activities.
Another common element was that the
majority of the criminal activity was
perpetrated by teenagers. These two
elements when taken together do suggest possible
approaches to controlling the use of technology
in such circumstances. The following is a
thought experiment based on already existing
social restrictions.
Since the wide use of the automobile, drivers
have been licensed. The purpose is manifold.
Licensing provides government funding for
transportation related projects such as roads
and traffic controls. Licensing also institutes
a minimum standard of operational quality, that
is, a licensed driver must demonstrate minimum
responsibility in terms of ability to operate a
vehicle without harming others.
Similar regulations exist for other products and
services, and for similar reasons. There
are limitations on the purchase and use of
cigarettes and alcohol, as well as on voting and
gambling. These limitations exist for the same
reasons as we license drivers, that is that
society has a stake in the imposition of minimum
responsibility regarding the use of these
products and services. In the face of the
criminal use of technology in the United States
and England, it follows that society has a stake
in the imposition of minimum responsibility
regarding the use of mobile technology just as
it does with driving, drinking, voting and
gambling. To that end, a licensing scheme
makes as much sense for mobile technology access
by minors.
There are four major arguments which will arise
regarding such regulation. These arguments
are freedom of speech, the ubiquity of mobile
technology, the impact on profits of mobile
phone service providers, and the underlying
bureaucratic structure required for such a
licensing scheme. We will examine these
arguments and see if they are overly restrictive
or unworkable.
Mobile devices are everywhere. Facebook,
Twitter and Blackberry Messenger are integrated
into our lives to keep us in touch to the degree
that in some cases they are the primary if not
only way that some users communicate with the
wider world in developing countries.
However, in developed
countries, a licensing scheme for mobile
technology does not prohibit freedom of
expression, it merely regulates one mode of
expression. Other modes of expression
still exist. Therefore, in developed countries,
free speech cannot be said to be prevented in
this case.
With the Arab Spring, it can even be argued that
mobile technology as a mode of expression has
had an undeniably positive impact on society,
and that it is not possible to bring the
ubiquity of mobile technology under control to
the distress of dictators worldwide.
However, San Francisco’s Bay Area Rapid Transit,
or BART, recently shut down cell phone
transmission briefly in its subway to head off
instant communication and coordination via
mobile devices in the event of a rumored
demonstration. Legal questions of BART’s action
aside, the point is that it is conceptually
possible to place restrictions on mobile
technology access.
The restriction on the sale of alcohol is like
but not identical to, the restriction on tobacco
sales to minors. The underlying concept is
the same, but the mechanics differ. A
similar comparison can be made to mobile
technology licensing. Every text, tweet
and call is identified by device on the mobile
network. It is a simple enough
technological step to impose a curfew at the
mobile network level on devices registered to
minors, so that a device may be rendered
inoperable except for emergency calls during
certain hours.
Despite the legal restriction on alcohol,
cigarettes, etc., it must be noted that underage
users do in fact have access to these
substances. It follows that any
restriction on mobile technology will only be
partially effective. However, in the case
of Philadelphia and England, restricted access
would perhaps have been sufficient. If
gangs of rioters or looters cannot coordinate
instantly their effectiveness is significantly
diminished, as is the duration of the period of
disorder.
It may be argued that profits will suffer if
mobile technology providers cannot provide their
services freely to young people. This is
especially true at present, since the current
generation of young people is the first
generation to grow up in a world which has
always had the Internet and mobile devices, and
as such are more comfortable with, and the
greatest consumers of the technology. There are
two responses to that argument. First,
young people would no doubt add to economic
activity if they could drive and drink and smoke
and gamble earlier than they can presently.
However, society chooses to forgo that excess
economic activity in the interest of a stable
society. Second, the very newness of mobile
technology suggests that at this point the legal
and licensing regulations potential has not been
adequately examined.
A licensing scheme is certainly possible, and in
fact even easy when compared to imposition of
limitations on underage drinking and smoking.
In fact licensing of mobile technology
usage is comparable to licensing driving.
A young person, faced with the reality
that drinking and smoking are legally prohibited
to them, will indulge in these activities in
secret. With mobile technology, this is
neither desirable nor useful. The point of
mobile technology is immediacy, to use this
technology, it must be used in the open, and
that openness means that a licensing scheme is
possible.
The model of prepaid services does not suffer
unnecessarily from the imposition of age
restrictions. As with smoking, drinking and
gambling, it is easily possible to restrict
access a reasonable amount of the time based on
age. In the case of prepaid mobile
services, it would be sufficient to require
purchase with a credit card if online or with
proof of age when buying in person. Such a
model is already reasonably effective for
controlling alcohol and tobacco sales.
Mobile service providers will argue that they
are not the technology police. Yet mobile
service providers are like retailers of alcohol
and tobacco in the sense that they sell a
product which is dangerous when used
irresponsibly and fine for adults when used
responsibly. With this restriction in mind
alcohol and tobacco retailers incorporate
regulatory requirements into their retail
operations as a requirement of permission to do
business. A similar verification
requirement for mobile services providers would
be no more inconvenient, and in fact would
likely be less so, since once a phone is
registered to a minor, technology can
automatically impose and maintain appropriate
restriction on an ongoing basis with little
human interaction.
Also on the subjects of payment and enforcement,
we may consider who pays for the mobile
technology carried by young people. A
fully provisioned smartphone with texting and
web costs roughly US $50 per month to operate.
It is unlikely that tweens and teens
signed up for and are paying for this service
themselves; in most cases, parents must be
footing the bill. Therefore as with
societally imposed restrictions on parents
providing alcohol and tobacco to minors, a
restriction on providing access to mobile
technology to minors would also be largely
enforceable.
The social structure and social will already
exist to regulate access to certain substances
and activities based on age or other proof of
responsibility. These systems are not
foolproof, but they are reasonably effective a
good deal of the time. Such limitations
are imposed when society sees a greater benefit
from the limitation than in free unfettered
access. In the case of mobile technology,
in light of the destructive behavior to which
this technology has recently been put, and in
the absence of a present body of thought
regarding the propagation of this technology,
perhaps the time has come for some consideration
of the matter.
Share
this on ![]() witter or
witter or ![]() acebook.
acebook.
The Frontline Hack
Originally
Published June 8, 2011 at Yahoo! Associated
Content
On May
29 hackers defaced the web site of the PBS
program Newshour and completely missed the
point. Since the content added by the
hackers was fictional and not a statement of
intent in itself, it’s up to us to determine the
motivation and, if the hackers are still
permitting it, to debate the effectiveness of
the attack.
The first thing that news of the attack made me
do was to pull up the website and read the
Frontline statement. The second thing that
I did was to view the episode in question.
The third thing I did was to read the comments
that were posted in relation to the
segment. The fourth thing I did was to
conclude that hackers in question do not
understand discourse and conversation among men
of good will.
The dozens of comments posted in relation to the
Frontline segment are both positive and negative
toward the segment. The oldest comment was
5 days old, the newest one hour. These
comments were interspersed with comments from
the Frontline editors. From this I
conclude that the editors were aware of the
responses, both positive and negative, which
their segment caused and chose not to censor
them. As they should not, although as a
consumer of Internet news, it appears that the
Frontline editors allow more criticism than some
news sites.
The comments themselves were for the most part
better thought out and more educated than many
comments from a lot of sites. This was a
debate, and with apologies to Martha Stewart,
that is a Good Thing. The sort of debate
provoked was exactly the sort that the release
of the Wikileaks cache was supposed to start
about Iraq and Afghanistan.
Since there was only a fake article posted by
the hackers and not an actual statement, this
leaves us to determine the motivation.
This is always dangerous because people might
not arrive at the intended conclusion. In
college I read The Sun Also Rises, and to me the
story of a chronic depressive was less than
inspirational. Others extol the symbolism of the
bull, etc. So what was the motivation of
the Frontline hackers?
Was the motivation that some things should not
see publication? Isn’t the entire
Wikileaks affair about just the opposite?
Was the point ‘Do what I say and not what I
do’? That becomes quickly wearisome and
loses credibility fast, and it also seems to run
counter to the philosophy of Wikileaks.
I admit that I wish that I could hack like those
guys obviously can. But I also wish that
they would spend a little less time at the code
level and a little more time figuring out that
the opportunity for an enthusiastic debate is
what makes a society free. People are
dying for that right in the Middle East as we
speak. For further reading and
clarification of exactly what I mean, may I
suggest that potential hackers spend some time
at the websites of PBS or Wikileaks.
Share this on ![]() witter or
witter or ![]() acebook.
acebook.
Information Systems: Where We are Today
Originally Published June 7, 2011 at Yahoo! Associated Content
The shortest path between two points is a single line. Therefore, we assume that if people are fundamentally rational, no one is going to make regulations for the sake of regulation. So why are privacy questions from mobile phone location tracking to default privacy settings under scrutiny in Congress? The answer is just the possibility that some regulation might be in order.
In the beginning, an unregulated Internet was literally called the wild west. There was no regulation to speak of. If hackers made a virus, the security firms made a fix. If in the meantime, the virus caused an issue with your computer, it was frustrating, but that was all it was. Then viruses became more ambitious, and the result actually evolved into what could be categorized as computer crime at the point when viruses started having an actual measurable impact on the financial world outside of the Internet.
The result was regulation, or laws, to address this evolution of malevolent activity. To keep to the analogy of the wild west, there was a new sheriff in town, and you could still have a showdown at high noon, but back shooting and horse stealing were illegal.
To continue on this historical comparison, we may no longer be in the wild west era of the Internet. To those who would profit most in a minimally regulated wild west, this is uncomfortable. They know the era, and are resistant to change, therefore they continue to act and think in terms of the era. But if we are in fact not in that era, what era are we in, and how do we address it? The next historical era is the industrial era, and consequent to that era, is the phenomenon of the robber baron.
The Internet is now key to national and global economies. Information related companies are valued in the billions of dollars. Global business models could not exist as they do without the Internet. Company profits are contingent on this model. Lastly, this is the Internet in the age when a Sherman Act (or Acts) may evolve to address competition, or data speed throttling by ISPs, or, at present, privacy issues. The point is, that as, or if, the robber barons push too far, regulation will inevitably push back.
All is not lost, however. The Googles, Apples and Facebooks, and for that matter the ISPs and mobile carriers, have two choices. They can react to every blowback on privacy, bandwidth or search engine hierarchy, or they can craft their own policies with any eye to the historical reality that if they do not regulate themselves rationally, someone will step in and do it for them. And nobody really wants that.
Share this on
Consumer Informatics Security
Originally Published June 8, 2011 at Yahoo! Associated Content
Consumer information systems today are in conflict with themselves. On the one hand, in order to sell information based products from computers to smartphones to services, consumer information systems must cater to the lowest common denominator in terms of technical savvy. On the other hand, an increase in sophisticated hacking, both technical and socially engineered, is showing up security flaws in systems taken for granted, and often not well understood by these same novice users. To remain competitive, information services and products must address both of these conflicting realities.
Consumers of information systems are like automobile drivers in one sense. Hundreds of millions of people can use technology effectively, but relatively few understand how it works or how to fix it or even maintain it. This is a necessary quality of consumer systems, for if users were required to understand the systems they used beyond the level needed to use it effectively, the market would be considerably smaller, and unlikely to ever grow significantly. Therefore, one element of consumer information products and services is that they should be designed explicitly with ease of use in mind.
At the same time, if systems are easy to use, they are also easy to exploit. Least on the list of threats are groups like Lulz and Anonymous; much higher on the list are the informatics practices of users themselves and those practices in conjunction with vulnerable, open or accessible systems. And yet the systems must be secure to maintain confidence in them, while remaining accessible to technology novices in order to remain competitive. The job of bridging that gap logically cannot belong to these novice end users, and so must belong to information providers, or if not, it will end up belonging to the government.
Information providers have several ways to impose minimum best practices on information consumers. Some are already in use, for example minimum password sophistication standards, and browser version requirements. However, there is room for improvement. Some options within the capabilities of today’s technology are validation via Bluetooth, wifi, near field technology or USB of the proximity of a registered smartphone, USB key or microchip in a keychain dongle to a user when login is attempted. Another would be similar portable devices which validate the user through thumbprint or other biometrics.
Other security improvements are social. As one example, I recently validated a bank account with Paypal. Paypal offered to validate the bank account either with tiny deposits to my account which I would have to verify, or by giving Paypal my login information for my online bank account. In this example it does not matter in the least if Paypal’s servers are secure and its internal data security policies are Draconian. Giving out login information for your bank, email etc., or asking for it in the first place, is most definitely not an informatics best practice, and should not be encouraged in any circumstances ever.
Another social exploit waiting to happen is when any information systems based vendor buries browser or other security requirements in their privacy policy or terms of use. This is not malice on the part of the vendor, but simply one of a string of legal protections vendors are providing to themselves. It needs to be more than that. Informing technologically novice customers directly and explicitly about threats and remedies should be of special importance and and more than a legalistic footnote buried in a policy few information consumers read.
This is more than a wish list, it has implications in the real world. Gmail, Sony, Lockheed Martin and more now have a data compromise to live down. That in turn will have implications in oversight, user restrictions, potentially awarding of contracts, and ultimately cost and stock price. One thing is certain: if information technology is to be developed with simplicity in mind, for purchase and use by the least technologically savvy, then there is a built in security gap which has to be filled. If informatics vendors want to retain credibility in such a model, then however they do it, it is up to them to fill that gap.
Share this on
Big Business Really Is Watching You
Originally Published June 8, 2011 at Yahoo! Associated Content
The Center for the Digital Future at the University of Southern California’s School for Communication and Journalism made headlines in June when it reported that 48% of adult Internet users are concerned that ‘Big Business is watching them’. First, let’s harden that worry into concrete reality: big business is definitely watching you. Then we’ll look at what it actually means. The concept is called customer relationship management, or CRM, and it’s a multi-billion dollar industry and growing.
So exactly what is customer relationship management? From mission statements and white papers of various CRM providers, we get nebulous statements like strategy, buy in to reduce churn, analytics of customer buying patterns in order to deepen customer relationships with a vendor. These are all highly variable terms. With all of these highly variable definitions, we get something akin to predicting the stock market or the weather, and we see that big business may be watching, but what they see does not always reflect what is. As a consequence, the conclusions and strategies are of variable and questionable value.
A strategy is a long term plan that makes certain assumptions, many of which may be wrong due to incorrect weight of variables, or which may be rendered useless next week or next month by new technology or legislation. Buy in assumes that everyone involved in the process of collecting and collating customer data will do it and do it correctly every time which is a very bad assumption, and obviously so to anyone who has every worked at the production level of a job, and has little vested interest in added bureaucracy. Churn is the technical term for losing customers, and while it’s nice to have a single euphonious term, in fact churn happens for any number of reasons some of which conflict with others, for example quality of customer service versus price, or time to market of products versus quality testing of those same products. Deepening customer relationships assumes that the relationship is understood, and there is no particular reason to believe that this is so.
As an example, I have a Netflix account. I am allowed to log in more than one computer for access to the Watch Instantly feature. Thus this feature is accessed on different machines at different times by different household members. As a consequence, the predictions of Netflix regarding whether I will like an offering is wrong a larger part of the time than Netflix would wish. And it’s not likely to improve its batting average any time soon since the definition of the ‘customer’ they think that they have is in fact more than one viewer accumulating the viewing history.
Add to this gift purchases which will not be used by and might, or might not, reflect the tendencies of the buyers, buying for family members or friends, buying work related versus home use products, etc. This is a vast amount of data, far too much to be verified by a human, so that decision support systems must assign weights and values, and nobody will ever be able to thoroughly double check the correctness of all of them. Worse, once an incorrect assumption is in the analysis, everything which follows based on it will be wrong to some degree or another.
This vast amount of data and the sometimes mistaken assumptions resulting from analysis of that data suggests that no data miner or CRM model has any more chance at actual accuracy in defining you as a customer than a computer can predict the weather or the stock market or the possibility of life on other worlds. In the end, all of these analyses rely on assumptions, and those assumptions contain at least a dose of ‘we guess’ or ‘we think’.
Since so much money and effort go into trying to define the customer, and so much perceived value is seen in that proposition, the process is not likely to stop any time soon, and if anything will increase As consumers operating in that environment, there are a couple of possible responses.
- Do nothing. Understand that given the variables in play, the chance of a computer actually defining who you are to any usable degree, management correctly assessing that definition and the business responding in a timely fashion to successfully manipulate your purchasing decisions is not terribly high. Laugh at the degree of error, and go on with your life safe in the knowledge that somewhere that degree of error is making a business analyst ready for the rubber room.
- Keep up the pressure on politicians and business to restrict access to and use of personal information. This is actually counterproductive if you are privacy minded. It’s counter intuitive, but if privacy is the goal, it’s better for personal information to be buried in a mass of irrelevant data. Less effective is a restriction on information collection since limited information collected is actually more likely to be meaningful. Don’t worry that business will figure this out and join consumers on the privacy bandwagon, it won’t.
Big business is watching you, and will be for the indeterminate future. Unfortunately for them, the process is not anywhere remotely as exacting as with Orwell’s Thought Police. It’s only in a work of fiction that exactly the right weight is given to exactly the right variables to arrive at exactly the right conclusion.
Share this on
The Future of Windows Phone
Originally Published June 8, 2011 at Yahoo! Associated Content
Windows has obstacles to overcome if it’s ever really to compete in the smartphone market. One of the key obstacles is Microsoft’s attitude toward consumers. In Windows for desktop, Microsoft has a justifiable arrogance. Windows is easier to use and more compatible with more peripherals than Linux (although that’s changing) and more affordable than Apple. Thus Windows fills a balanced, specific niche on the desktop, and consumers will jump through a lot of hoops to use Windows on the PC.
One example of being forced to jump through hoops was the ribbon bar in Office 2007. Another from back in the day was Excel excluding Lotus 1-2-3 compatible commands. Microsoft did not ask consumers if they liked or wanted these changes or limitations, instead they said ‘You will use it’ because there was no option to opt for old style menus. However, agreeing to jump through hoops does not mean that consumers like jumping through hoops, and Microsoft has never seemed to understand or care about the difference. This was and is justifiable arrogance because Microsoft for PCs was and is still the 600 pound gorilla, and it sits wherever it wants to sit.
When faced with serious competition outside of the desktop market, Microsoft has not really learned how to compete effectively. If Microsoft wins in the desktop market for reasons of price, compatibility and relative ease of use, and loses in terms of customer centered development and security, how do those strengths and weaknesses translate in the mobile market?
The mobile market has iPhone, Blackberry and Android providing significant competition in terms of price, ease of use, stability, compatibility, security and developer access. In short, the metrics of competition are not the same as on the desktop. So, all things being equal, how much does the smartphone consumer like having to register for Windows Live and Zune to sync files between PC and phone, or register for Hotmail or own Outlook to sync contacts with a Windows Phone format? In short, how often will consumers willingly jump through hoops when they have other options? The answer seems to be: about 3% of the time.
Microsoft understandably wants to leverage tie in to its other products. That can be a service to customers, but only if tie ins are easy to use, organized and above all, optional without detracting from the phone’s functionality. A couple of searches for cross platform compatibility options at Microsoft’s Windows Mobile website suggest that this is not a priority. Microsoft does not cater to what the consumer wants, Microsoft caters to what it wants the consumer to want.
With the cloud, smartphone consumers are demanding more interoperability not more restrictions, and the OS itself becomes less important. Smartphone environments for Android, Blackberry and Apple seem to be responding (with different degrees of nimbleness). Microsoft in the meanwhile seems to be saying to a limited audience: What did the 600 pound gorilla do with the smartphone?
Share this on